5.10. Pandas join and concat#
5.10.1. Pandas join#
In pandas, the join() method is used to combine two DataFrame objects based on their index or on a key column. It is one of the methods for data alignment and merging in pandas. This operation can be compared to a database-style join. The basic syntax for the join() method is as follows [McKinney and others, 2010, Pandas Developers, 2023]:
result = left_dataframe.join(right_dataframe, how='inner')
Here, left_dataframe is the DataFrame to which you want to join another DataFrame (right_dataframe). The how parameter specifies the type of join to perform, and it can take the following values:
'inner': Performs an inner join, keeping only the rows that have matching keys in both DataFrames.'outer': Performs an outer join, keeping all the rows from both DataFrames and filling in NaN values for missing keys.'left': Performs a left join, keeping all the rows from the left DataFrame and filling in NaN values for missing keys in the right DataFrame.'right': Performs a right join, keeping all the rows from the right DataFrame and filling in NaN values for missing keys in the left DataFrame.'cross': The cross merge method produces the Cartesian product of both data frames while maintaining the original order of the left keys.
For a comprehensive description of the function, please refer to the official documentation here.
Examples:
import pandas as pd
df1 = pd.DataFrame({
'key': ['K0', 'K1', 'K2', 'K3'],
'A': ['A0', 'A1', 'A2', 'A3']
})
df2 = pd.DataFrame({
'key': ['K0', 'K1', 'K2', 'K4'],
'B': ['B0', 'B1', 'B2', 'B3']
})
df1.set_index('key', inplace=True)
df2.set_index('key', inplace=True)
print('df1:')
display(df1)
print('df2:')
display(df1)
df1:
| A | |
|---|---|
| key | |
| K0 | A0 |
| K1 | A1 |
| K2 | A2 |
| K3 | A3 |
df2:
| A | |
|---|---|
| key | |
| K0 | A0 |
| K1 | A1 |
| K2 | A2 |
| K3 | A3 |
Inner Join: An inner join keeps only the rows with keys that are present in both DataFrames.
result = df1.join(df2, how='inner', validate='1:1')
display(result)
| A | B | |
|---|---|---|
| key | ||
| K0 | A0 | B0 |
| K1 | A1 | B1 |
| K2 | A2 | B2 |
The validate parameter in the join method is used to ensure that the merge operation meets certain criteria. In our example, validate='1:1' ensures that both DataFrames have unique keys, meaning each key in the left DataFrame (df1) matches exactly one key in the right DataFrame (df2).
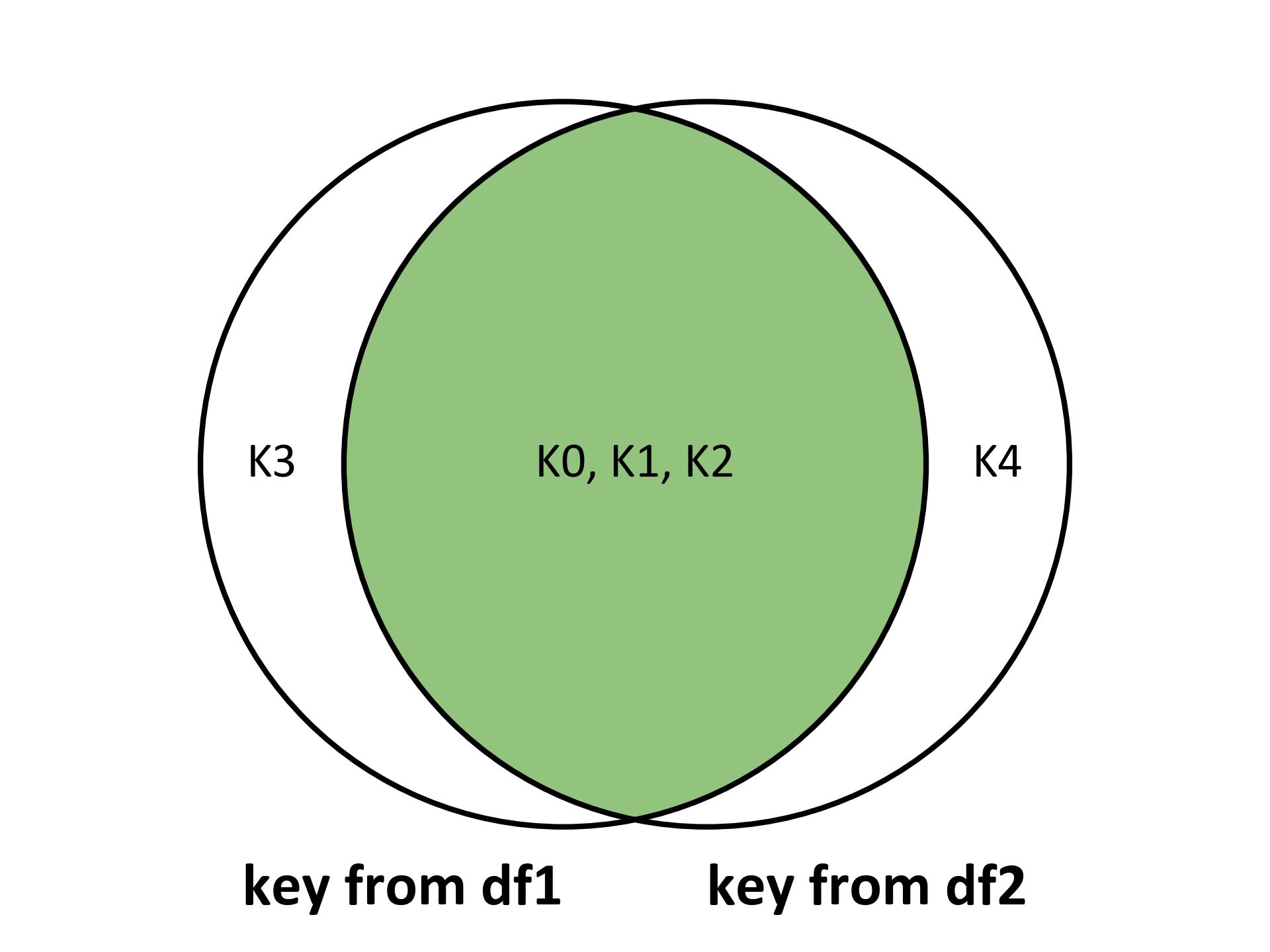
Fig. 5.23 Visualizing the inner join for the above example.#
Note
The validate parameter in the join() method is used to ensure the integrity of the join operation by checking the relationship between the DataFrames being joined. In your example, validate='m:m' specifies that the join should be a many-to-many relationship. This means that each key in the DataFrames can appear multiple times.
A brief overview of the possible values for the validate parameter:
‘1:1’: One-to-one relationship.
‘1:m’: One-to-many relationship.
‘m:1’: Many-to-one relationship.
‘m:m’: Many-to-many relationship.
Using validate helps catch potential issues in the join operation by ensuring the specified relationship is maintained.
Outer Join: An outer join keeps all the rows from both DataFrames, filling in NaN for missing values.
result = df1.join(df2, how='outer', validate='m:m')
display(result)
| A | B | |
|---|---|---|
| key | ||
| K0 | A0 | B0 |
| K1 | A1 | B1 |
| K2 | A2 | B2 |
| K3 | A3 | NaN |
| K4 | NaN | B3 |
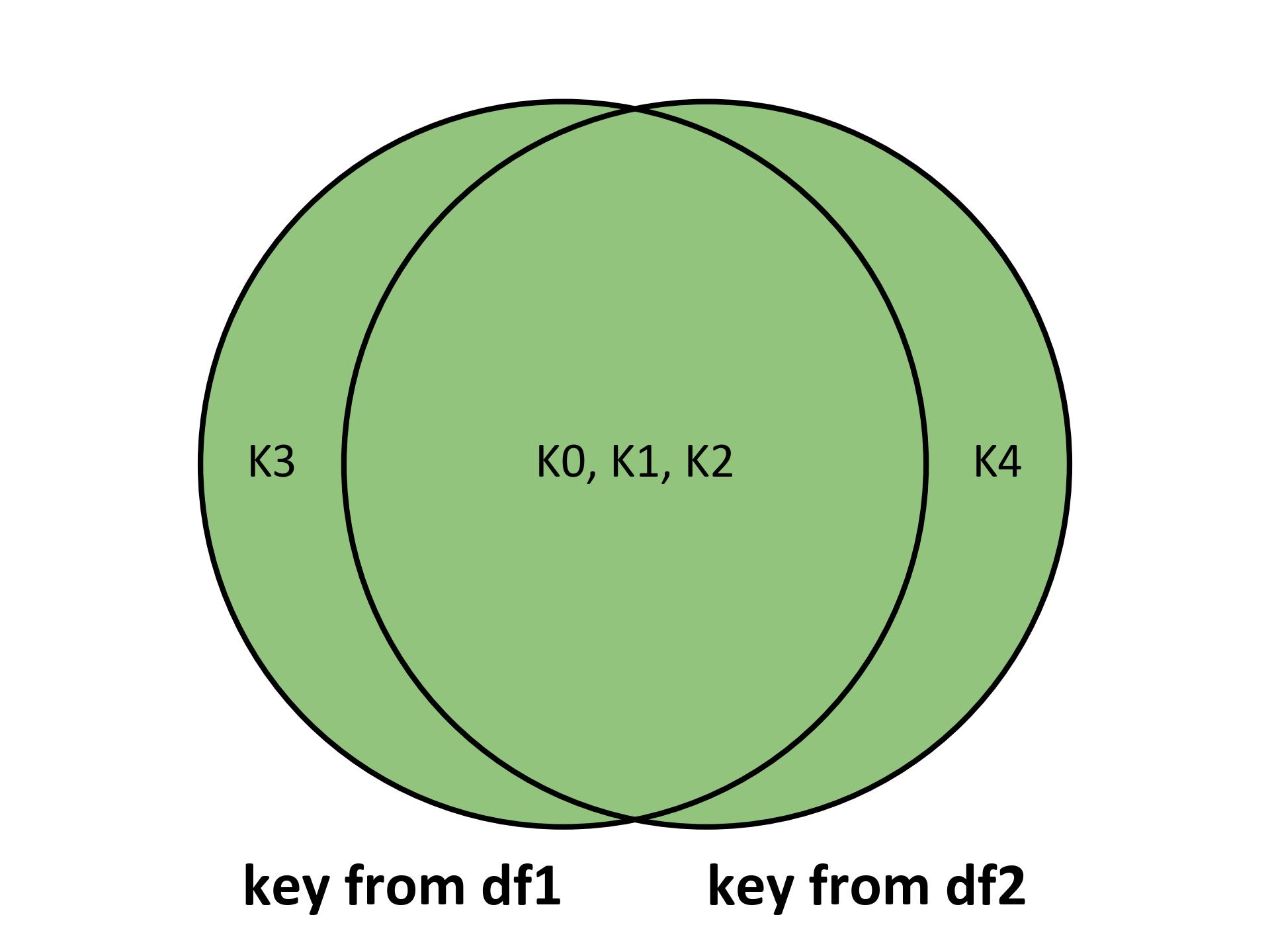
Fig. 5.24 Visualizing the outer join for the above example.#
Left Join: A left join keeps all the rows from the left DataFrame and fills in NaN for missing values from the right DataFrame.
result = df1.join(df2, how='left', validate='m:1')
display(result)
| A | B | |
|---|---|---|
| key | ||
| K0 | A0 | B0 |
| K1 | A1 | B1 |
| K2 | A2 | B2 |
| K3 | A3 | NaN |
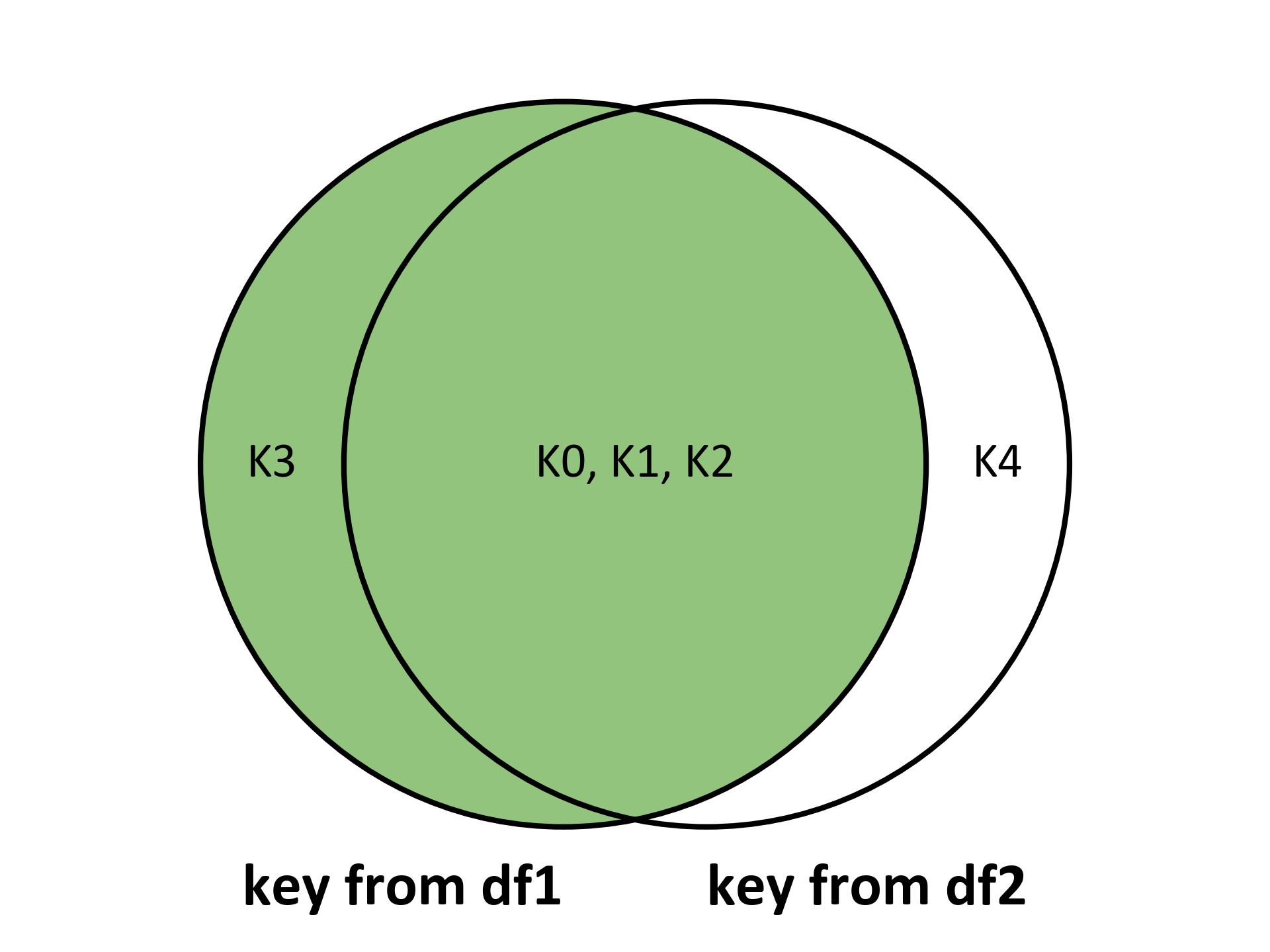
Fig. 5.25 Visualizing the left join for the above example.#
Right Join: A right join keeps all the rows from the right DataFrame and fills in NaN for missing values from the left DataFrame.
result = df1.join(df2, how='right', validate='1:m')
display(result)
| A | B | |
|---|---|---|
| key | ||
| K0 | A0 | B0 |
| K1 | A1 | B1 |
| K2 | A2 | B2 |
| K4 | NaN | B3 |
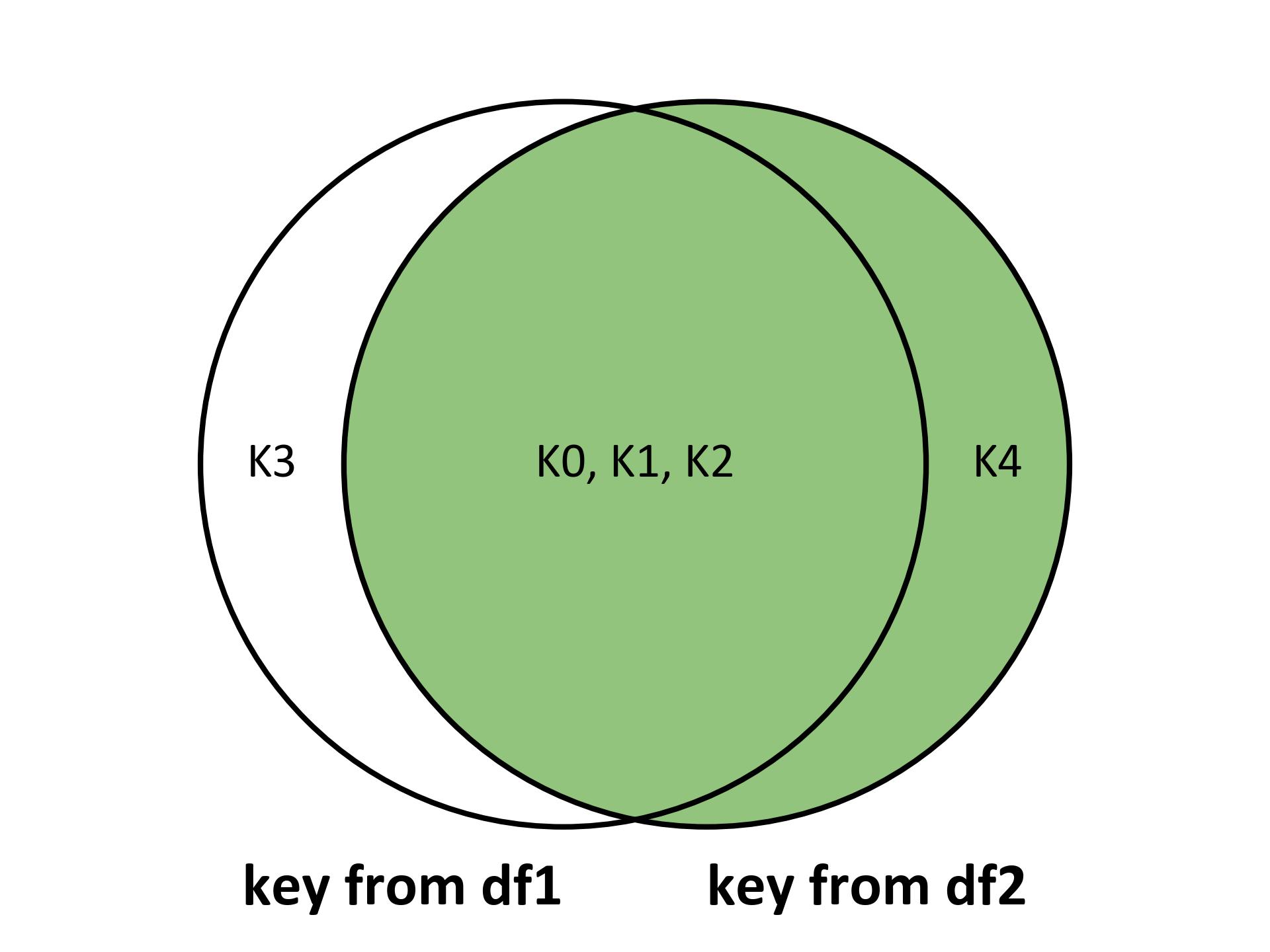
Fig. 5.26 Visualizing the right join for the above example.#
Cross Join: A cross join creates the Cartesian product of both DataFrames.
result = df1.join(df2, how='cross')
display(result)
| A | B | |
|---|---|---|
| 0 | A0 | B0 |
| 1 | A0 | B1 |
| 2 | A0 | B2 |
| 3 | A0 | B3 |
| 4 | A1 | B0 |
| 5 | A1 | B1 |
| 6 | A1 | B2 |
| 7 | A1 | B3 |
| 8 | A2 | B0 |
| 9 | A2 | B1 |
| 10 | A2 | B2 |
| 11 | A2 | B3 |
| 12 | A3 | B0 |
| 13 | A3 | B1 |
| 14 | A3 | B2 |
| 15 | A3 | B3 |
The code demonstrates how the join() method can be used to combine two DataFrames using their indices, resulting in a new DataFrame where columns from both DataFrames are aligned based on the shared index labels. In this example, the resulting DataFrame will have columns ‘A’, ‘B’, ‘C’, and ‘D’.
5.10.2. Specifying Join Type and Suffixes#
Specifying the join type and using custom suffixes can be essential when combining DataFrames. This helps to avoid confusion and ensures clarity when there are overlapping column names.
Example:
import pandas as pd
# Creating example DataFrames
df1 = pd.DataFrame({'A': [1, 2, 3], 'B': [4, 5, 6]}, index=['X', 'Y', 'Z'])
df2 = pd.DataFrame({'B': [7, 8, 9], 'D': [10, 11, 12]}, index=['X', 'Y', 'Z'])
# Title: Joining DataFrames with Custom Suffixes
# Print the original DataFrames
print("Original df1:")
display(df1)
print("\nOriginal df2:")
display(df2)
# Performing an inner join with custom suffixes
joined_df_inner = df1.join(df2, how='inner', lsuffix='_left', rsuffix='_right')
# Title: Displaying the Result
# Print the resulting joined DataFrame
print("\nJoined DataFrame (inner join with custom suffixes):")
display(joined_df_inner)
Original df1:
| A | B | |
|---|---|---|
| X | 1 | 4 |
| Y | 2 | 5 |
| Z | 3 | 6 |
Original df2:
| B | D | |
|---|---|---|
| X | 7 | 10 |
| Y | 8 | 11 |
| Z | 9 | 12 |
Joined DataFrame (inner join with custom suffixes):
| A | B_left | B_right | D | |
|---|---|---|---|---|
| X | 1 | 4 | 7 | 10 |
| Y | 2 | 5 | 8 | 11 |
| Z | 3 | 6 | 9 | 12 |
This code snippet demonstrates how to use the Pandas library in Python to create, join, and display DataFrames:
Creating the First DataFrame:
df1 = pd.DataFrame({'A': [1, 2, 3], 'B': [4, 5, 6]}, index=['X', 'Y', 'Z'])
Here, we create the first DataFrame,
df1, with two columns ‘A’ and ‘B’, each containing a list of values. Theindexparameter assigns custom row indices ‘X’, ‘Y’, and ‘Z’ to the DataFrame.Creating the Second DataFrame:
df2 = pd.DataFrame({'B': [7, 8, 9], 'D': [10, 11, 12]}, index=['X', 'Y', 'Z'])
Similarly, the second DataFrame,
df2, is created with columns ‘B’ and ‘D’, along with the same custom row indices asdf1.Performing the Join Operation:
joined_df_inner = df1.join(df2, how='inner', lsuffix='_left', rsuffix='_right')
This line performs an inner join operation between
df1anddf2using thejoin()method. Thehow='inner'argument specifies an inner join, which retains only the rows with matching indices in both DataFrames. Additionally, thelsuffix='_left'andrsuffix='_right'arguments are used to add custom suffixes to the columns with identical names in the two DataFrames to differentiate them.
5.10.3. Joining on a Column and Index#
It’s often necessary to combine DataFrames based on both columns and indices. This approach allows you to merge data efficiently when you have a common column and an index that align.
Example:
import pandas as pd
# Creating example DataFrames
students_df = pd.DataFrame({'student_id': [1, 2, 3],
'student_name': ['Alice', 'Bob', 'Charlie']})
scores_df = pd.DataFrame({'score': [85, 92, 78]},
index=[1, 2, 3]) # Index matches 'student_id'
# Title: Joining on a Column and Index
# Print the original DataFrames
print("Original students_df:")
display(students_df)
print("\nOriginal scores_df:")
display(scores_df)
# Joining students_df with scores_df on student_id and index
joined_df = students_df.join(scores_df, on='student_id')
# Title: Displaying the Result
# Print the resulting joined DataFrame
print("\nJoined DataFrame:")
display(joined_df)
Original students_df:
| student_id | student_name | |
|---|---|---|
| 0 | 1 | Alice |
| 1 | 2 | Bob |
| 2 | 3 | Charlie |
Original scores_df:
| score | |
|---|---|
| 1 | 85 |
| 2 | 92 |
| 3 | 78 |
Joined DataFrame:
| student_id | student_name | score | |
|---|---|---|---|
| 0 | 1 | Alice | 85 |
| 1 | 2 | Bob | 92 |
| 2 | 3 | Charlie | 78 |
The code demonstrates how to use the join() method to combine DataFrames on a specified column and index, effectively matching information from both DataFrames based on the shared ‘student_id’. The displayed output will show the combined information of student names and scores.
Example: The following Python code exemplifies the process of merging two Pandas DataFrames based on both a shared column and an index. These DataFrames pertain to city information, with a specific focus on cities located in the province of Alberta, Canada. It’s important to acknowledge that there might be discrepancies between the population figures presented in this example and the precise figures for the year 2023. For precise and up-to-date population statistics, it is advisable to consult official sources such as https://www.citypopulation.de/en/canada/cities/alberta/.
import pandas as pd
# Create a City DataFrame with city names and populations
cities_df = pd.DataFrame({'City_Name': ['Calgary', 'Edmonton', 'Lethbridge'],
'Population': [1481466, 1128811, 107225]})
# Display the City DataFrame
print("cities_df:")
display(cities_df)
# Create an Additional Details DataFrame with 'City_Name' as the index
details_df = pd.DataFrame({'City_Name': ['Calgary', 'Edmonton', 'Lethbridge'],
'Province': ['Alberta', 'Alberta', 'Alberta'],
'Area (km^2)': [825.3, 684.47, 127.2]})
# Set 'City_Name' as the index for the Additional Details DataFrame
details_df = details_df.set_index('City_Name')
# Display the Additional Details DataFrame
print("\ndetails_df:")
display(details_df)
# Join the City DataFrame with the Additional Details DataFrame using both the 'City_Name' column and index
joined_df = cities_df.join(details_df, on='City_Name')
# Display the resulting joined DataFrame
print("\njoined_df:")
display(joined_df)
cities_df:
| City_Name | Population | |
|---|---|---|
| 0 | Calgary | 1481466 |
| 1 | Edmonton | 1128811 |
| 2 | Lethbridge | 107225 |
details_df:
| Province | Area (km^2) | |
|---|---|---|
| City_Name | ||
| Calgary | Alberta | 825.30 |
| Edmonton | Alberta | 684.47 |
| Lethbridge | Alberta | 127.20 |
joined_df:
| City_Name | Population | Province | Area (km^2) | |
|---|---|---|---|---|
| 0 | Calgary | 1481466 | Alberta | 825.30 |
| 1 | Edmonton | 1128811 | Alberta | 684.47 |
| 2 | Lethbridge | 107225 | Alberta | 127.20 |
5.10.4. Joining with DataFrame and Series#
import pandas as pd
# Creating a DataFrame and a Series
df = pd.DataFrame({'A': [1, 2, 3], 'B': [4, 5, 6]})
series = pd.Series([10, 20, 30], name='C')
# Title: Joining a DataFrame with a Series
# Print the original DataFrame and Series
print("Original DataFrame (df):")
display(df)
print("\nOriginal Series (series):")
display(series)
# Joining the DataFrame with the Series
joined_df = df.join(series)
# Title: Displaying the Result
# Displaying the result
print("\nJoined DataFrame:")
display(joined_df)
Original DataFrame (df):
| A | B | |
|---|---|---|
| 0 | 1 | 4 |
| 1 | 2 | 5 |
| 2 | 3 | 6 |
Original Series (series):
0 10
1 20
2 30
Name: C, dtype: int64
Joined DataFrame:
| A | B | C | |
|---|---|---|---|
| 0 | 1 | 4 | 10 |
| 1 | 2 | 5 | 20 |
| 2 | 3 | 6 | 30 |
5.10.5. Joining with a MultiIndex DataFrame#
import pandas as pd
# Creating example DataFrames with MultiIndex
index = pd.MultiIndex.from_tuples([('X', 1), ('Y', 2), ('Z', 3)], names=['idx', 'value'])
df1 = pd.DataFrame({'A': [10, 20, 30]}, index=index)
print('df1')
display(df1)
df2 = pd.DataFrame({'B': [100, 200, 300]},
index=pd.MultiIndex.from_tuples([('X', 1), ('Y', 2), ('Z', 4)], names=['idx', 'value']))
print('df2')
display(df2)
# Joining df1 with df2 on the MultiIndex 'idx' and 'value'
joined_df = df1.join(df2, on=['idx', 'value'])
# Displaying the result
print("\nJoined DataFrame:")
display(joined_df)
df1
| A | ||
|---|---|---|
| idx | value | |
| X | 1 | 10 |
| Y | 2 | 20 |
| Z | 3 | 30 |
df2
| B | ||
|---|---|---|
| idx | value | |
| X | 1 | 100 |
| Y | 2 | 200 |
| Z | 4 | 300 |
Joined DataFrame:
| A | B | ||
|---|---|---|---|
| idx | value | ||
| X | 1 | 10 | 100.0 |
| Y | 2 | 20 | 200.0 |
| Z | 3 | 30 | NaN |
This example demonstrates how to use the join() method to combine DataFrames with MultiIndexes based on specific MultiIndex levels.
The join() method in Pandas is useful when working with indexed data and when you want a more concise way to combine DataFrames. It offers flexibility in terms of specifying join types, handling multi-index data, and broadcasting along different axes. Remember to consult the Pandas documentation for more information on the join() method and its parameters: https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.join.html
5.10.6. Pandas concat#
The concat() function in pandas is used to concatenate pandas objects along a particular axis with optional set logic along the other axes. It can be used to concatenate DataFrames or Series. The basic syntax for the concat() function is as follows:
result = pd.concat([df1, df2], axis=0)
Here, df1 and df2 are the DataFrames you want to concatenate. The axis parameter specifies the axis along which the concatenation should occur:
axis=0: Concatenates along the rows (default).axis=1: Concatenates along the columns.
Additional parameters include:
ignore_index: If True, the resulting axis will be labeled 0, 1, …, n - 1.join: Specifies how to handle indexes on other axis. Options are ‘outer’ (default) and ‘inner’.keys: Used to create a hierarchical index.
For more details, you can refer to the official documentation here.
Example: Vertical Concatenation (Concatenate along rows)
import pandas as pd
# Sample DataFrames
data1 = {'A': [1, 2, 3], 'B': [4, 5, 6]}
data2 = {'A': [7, 8, 9], 'B': [10, 11, 12]}
df1 = pd.DataFrame(data1)
df2 = pd.DataFrame(data2)
# Concatenate vertically (along rows)
result_vertical = pd.concat([df1, df2], axis=0)
# Display the concatenated DataFrame
display(result_vertical)
| A | B | |
|---|---|---|
| 0 | 1 | 4 |
| 1 | 2 | 5 |
| 2 | 3 | 6 |
| 0 | 7 | 10 |
| 1 | 8 | 11 |
| 2 | 9 | 12 |
Example: Horizontal Concatenation (Concatenate along columns)
import pandas as pd
# Sample DataFrames
data1 = {'A': [1, 2, 3], 'B': [4, 5, 6]}
data2 = {'C': [7, 8, 9], 'D': [10, 11, 12]}
df1 = pd.DataFrame(data1)
df2 = pd.DataFrame(data2)
# Concatenate horizontally (along columns)
result_horizontal = pd.concat([df1, df2], axis=1)
# Display the concatenated DataFrame
display(result_horizontal)
| A | B | C | D | |
|---|---|---|---|---|
| 0 | 1 | 4 | 7 | 10 |
| 1 | 2 | 5 | 8 | 11 |
| 2 | 3 | 6 | 9 | 12 |
Note that when concatenating along a particular axis, the DataFrames should have compatible shapes along that axis (i.e., the number of rows for vertical concatenation and the number of columns for horizontal concatenation).
The concat() function also allows you to handle duplicate indices, specify whether to ignore the original indices, and more. For more complex concatenation scenarios, you can refer to the pandas documentation: https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.concat.html