5.5. Handling Missing Data in Pandas#
Pandas strives to offer flexibility when dealing with diverse data structures. The NaN (Not a Number) value is used as the default missing value indicator due to its computational efficiency and convenience. Efficiently addressing missing data is a foundational aspect of data analysis, given that real-world datasets frequently contain incomplete or unavailable information. Pandas offers an array of methods and tools to effectively manage missing data. This article provides in-depth explanations of these techniques [McKinney, 2022, Pandas Developers, 2023].
5.5.1. Identifying Missing Data#
In Pandas, the isna() and isnull() methods are used interchangeably to check for missing values within a DataFrame or Series. These methods have no functional difference; they yield identical results. Both methods generate a Boolean mask, where True indicates a missing value, and False indicates a non-missing value {cite:p}.
The choice between isna() and isnull() boils down to personal preference or coding style. Both methods exist to accommodate different user preferences. While isnull() is more commonly used, isna() is an alternative name for the same functionality. It was added for compatibility with other libraries and to enhance code readability for some users [McKinney, 2022, Pandas Developers, 2023].
Example:
import pandas as pd
data = pd.Series([1, None, 3, None, 5])
# Original Series
print("Original Series:")
print(data)
# Using isnull() to identify missing values
missing_values = data.isnull()
# displaying missing_values
print("\nIdentifying Missing Values:")
print(missing_values)
Original Series:
0 1.0
1 NaN
2 3.0
3 NaN
4 5.0
dtype: float64
Identifying Missing Values:
0 False
1 True
2 False
3 True
4 False
dtype: bool
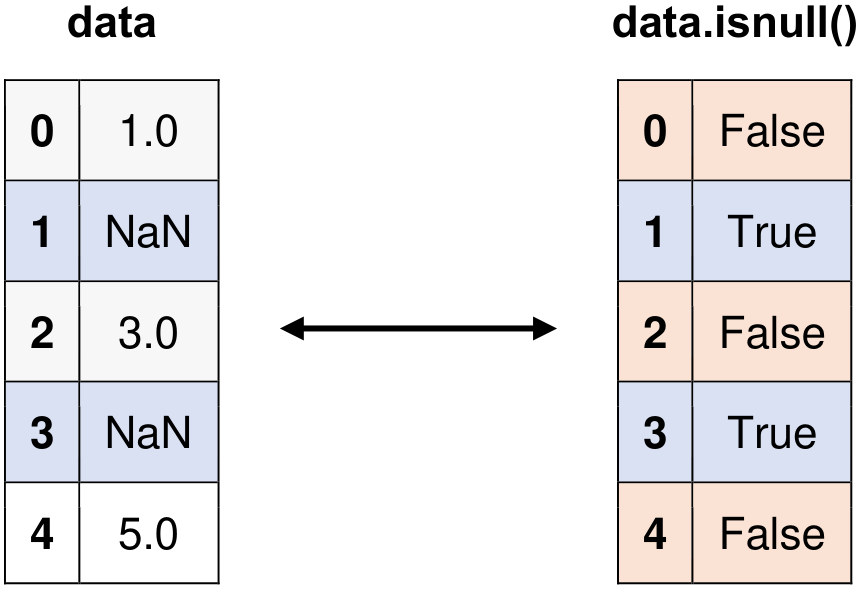
Fig. 5.8 Visual representation of the above example.#
import pandas as pd
data = pd.Series([1, None, 3, None, 5])
# Original Series
print("Original Series:")
print(data)
# Using isna() to identify missing values (same as isnull())
missing_values = data.isna()
# displaying missing_values
print("\nIdentifying Missing Values with isna():")
print(missing_values)
Original Series:
0 1.0
1 NaN
2 3.0
3 NaN
4 5.0
dtype: float64
Identifying Missing Values with isna():
0 False
1 True
2 False
3 True
4 False
dtype: bool
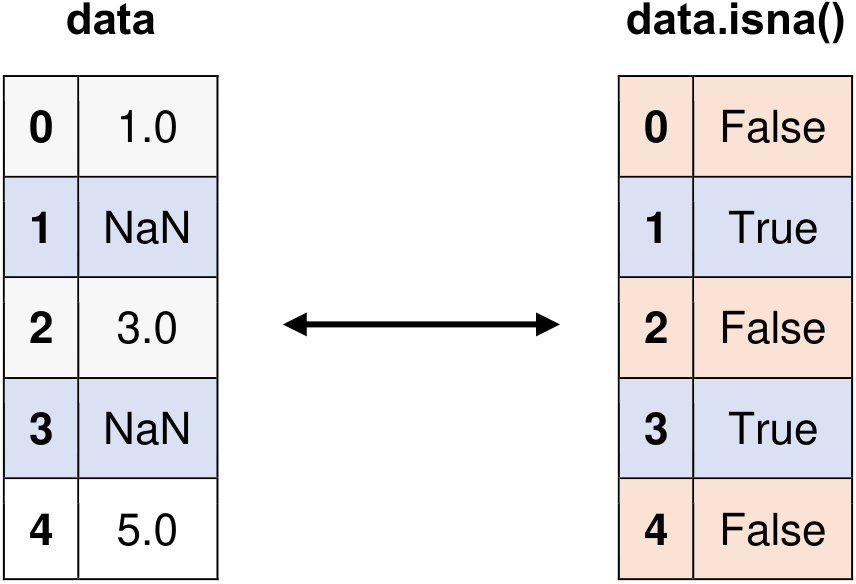
Fig. 5.9 Visual representation of the above example.#
Note
Both methods, isna() and isnull(), function interchangeably, offering flexibility based on your preference or coding convention.
5.5.2. Eliminating Missing Data#
In Pandas, the dropna() method is employed to eliminate missing values from a DataFrame. This method allows the removal of rows or columns that contain one or more missing values based on the specified axis. The fundamental syntax for dropna() is [McKinney, 2022, Pandas Developers, 2023]:
DataFrame.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)
Parameters:
axis: Determines whether to drop rows with missing values (axis=0) or columns (axis=1).how: Specifies the conditions under which rows or columns are dropped. Possible values are'any'(default) and'all'. When set to'any', any row or column containing at least one missing value will be dropped. If set to'all', only rows or columns with all missing values will be dropped.thresh: An integer value setting the minimum number of non-missing values required to keep a row or column. Rows or columns with fewer non-missing values than the threshold will be dropped.subset: Accepts a list of column names and applies the dropna operation only to the specified columns. Other columns will be unaffected.inplace: WhenTrue, the original DataFrame will be modified in place, and no new DataFrame will be returned. IfFalse(default), a new DataFrame with missing values removed will be returned, leaving the original DataFrame unchanged.
For a comprehensive reference, you can access the complete syntax description of the dropna() method here.
Example:
import pandas as pd
# Create a DataFrame with missing values
data = pd.DataFrame({'A': [1, 2, None, 4],
'B': [None, 6, 7, 8],
'C': [10, 11, None, None]})
# Drop rows containing any missing values
print('Drop rows containing any missing values:')
cleaned_data = data.dropna()
display(cleaned_data)
# Drop columns containing all missing values
print('Drop columns containing all missing values:')
cleaned_data_cols = data.dropna(axis=1, how='all')
display(cleaned_data_cols)
# Drop rows with at least 2 non-missing values
print('Drop rows with at least 2 non-missing values:')
cleaned_data_thresh = data.dropna(thresh=2)
display(cleaned_data_thresh)
Drop rows containing any missing values:
| A | B | C | |
|---|---|---|---|
| 1 | 2.0 | 6.0 | 11.0 |
Drop columns containing all missing values:
| A | B | C | |
|---|---|---|---|
| 0 | 1.0 | NaN | 10.0 |
| 1 | 2.0 | 6.0 | 11.0 |
| 2 | NaN | 7.0 | NaN |
| 3 | 4.0 | 8.0 | NaN |
Drop rows with at least 2 non-missing values:
| A | B | C | |
|---|---|---|---|
| 0 | 1.0 | NaN | 10.0 |
| 1 | 2.0 | 6.0 | 11.0 |
| 3 | 4.0 | 8.0 | NaN |
In this example, the dropna() method is used to create three distinct DataFrames with missing values removed. The first DataFrame (cleaned_data) drops rows with any missing value. The second DataFrame (cleaned_data_cols) drops columns where all values are missing. The third DataFrame (cleaned_data_thresh) drops rows with fewer than two non-missing values.