5.6. Filling Missing Data#
5.6.1. Constant Fill, Forward Fill, and Backward Fill#
In Pandas, the fillna() function is a versatile tool for replacing missing or NaN (Not a Number) values within a DataFrame or Series. This method is particularly useful during data preprocessing or cleaning tasks, enabling effective handling of missing data. You can tailor the way missing values are filled by using various parameters. For instance, you have the option to provide a single value, a list of values, or a dictionary to replace NaNs. Additionally, you can limit the consecutive NaN values to be filled and downcast the result to a specific data type if needed. Always consider the data distribution and the analysis context to ensure the proper handling of missing data without introducing biases or inaccuracies [McKinney, 2022, Pandas Developers, 2023].
Syntax:
DataFrame.fillna(value=None, axis=None, inplace=False, limit=None, downcast=None)
The fillna() method in Pandas allows you to replace missing or NaN values within a DataFrame or Series using various options:
The
valueparameter can be a single value, a list of values with the same length as the data, or a dictionary with column names as keys and values as fill values.The
axisparameter specifies whether to fill missing values along rows (axis=0, default) or columns (axis=1).When
inplace=True, the original DataFrame or Series is directly modified; withinplace=False(default), a new object with filled values is returned.The
limitparameter controls the number of consecutive NaN values filled.The
downcastparameter allows you to downcast the result to a specified data type, such as ‘integer’, ‘signed’, ‘unsigned’, ‘float’, or None (default) if possible.
You can see the full description of the function here.
Example:
import pandas as pd
import warnings
# Creating an example DataFrame with missing values (NaN)
data = {'A': [1, 2, None, 4, 5],
'B': [None, 10, 20, None, 50]}
df = pd.DataFrame(data)
# Displaying the original data for reference
print("Original Data:")
display(df)
# Filling NaN values with a constant (0 in this case)
print('Filling NaN values with a constant (0):')
df_filled = df.fillna(0)
display(df_filled)
Original Data:
| A | B | |
|---|---|---|
| 0 | 1.0 | NaN |
| 1 | 2.0 | 10.0 |
| 2 | NaN | 20.0 |
| 3 | 4.0 | NaN |
| 4 | 5.0 | 50.0 |
Filling NaN values with a constant (0):
| A | B | |
|---|---|---|
| 0 | 1.0 | 0.0 |
| 1 | 2.0 | 10.0 |
| 2 | 0.0 | 20.0 |
| 3 | 4.0 | 0.0 |
| 4 | 5.0 | 50.0 |
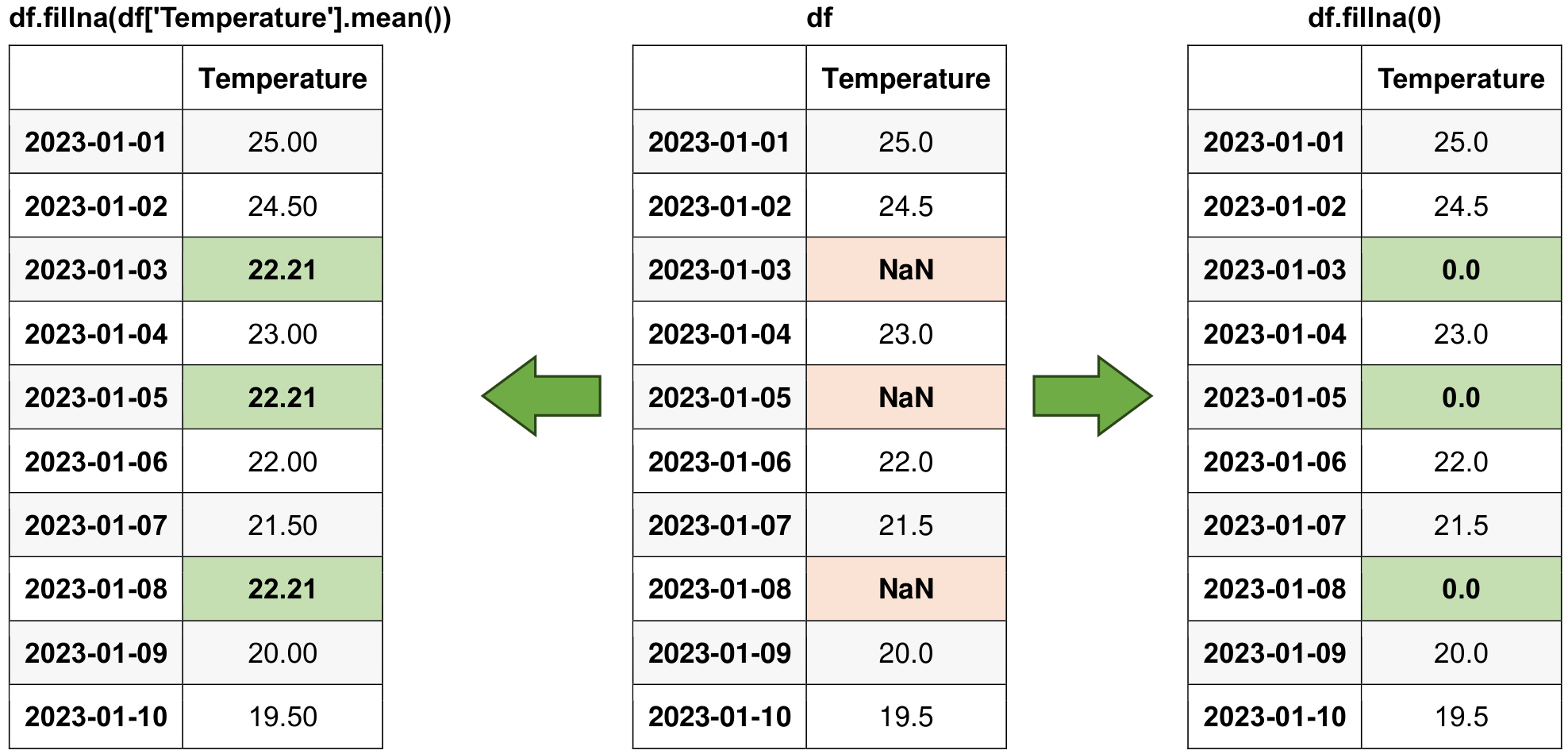
Fig. 5.10 Visual representation of the above example.#
5.6.2. Filling with Column Means or Medians#
Filling missing values with the mean or median of their respective columns is a common technique in data preprocessing, especially when dealing with numeric data. This method helps to maintain the overall distribution of the data while providing a reasonable estimate for the missing values.
5.6.2.1. Why Use Mean or Median?#
Mean: The mean (average) is useful when the data is symmetrically distributed without outliers. It provides a central value that represents the dataset.
Median: The median is more robust to outliers and skewed data. It represents the middle value when the data is sorted, making it a better choice for datasets with significant outliers.
Example: An example demonstrating how to fill missing values with the mean of their respective columns:
import pandas as pd
# Creating a DataFrame with missing values (NaN)
data = {'A': [1, 2, None, 4, 5],
'B': [None, 10, 20, None, 50]}
df = pd.DataFrame(data)
# Displaying the original data for reference
print("Original Data:")
display(df)
# Calculating column means for NaN imputation
column_means = df.mean().round(2)
# Filling NaN values with the corresponding column means
print('Filling NaN values with column means:')
df_filled_means = df.fillna(column_means)
display(df_filled_means)
Original Data:
| A | B | |
|---|---|---|
| 0 | 1.0 | NaN |
| 1 | 2.0 | 10.0 |
| 2 | NaN | 20.0 |
| 3 | 4.0 | NaN |
| 4 | 5.0 | 50.0 |
Filling NaN values with column means:
| A | B | |
|---|---|---|
| 0 | 1.0 | 26.67 |
| 1 | 2.0 | 10.00 |
| 2 | 3.0 | 20.00 |
| 3 | 4.0 | 26.67 |
| 4 | 5.0 | 50.00 |
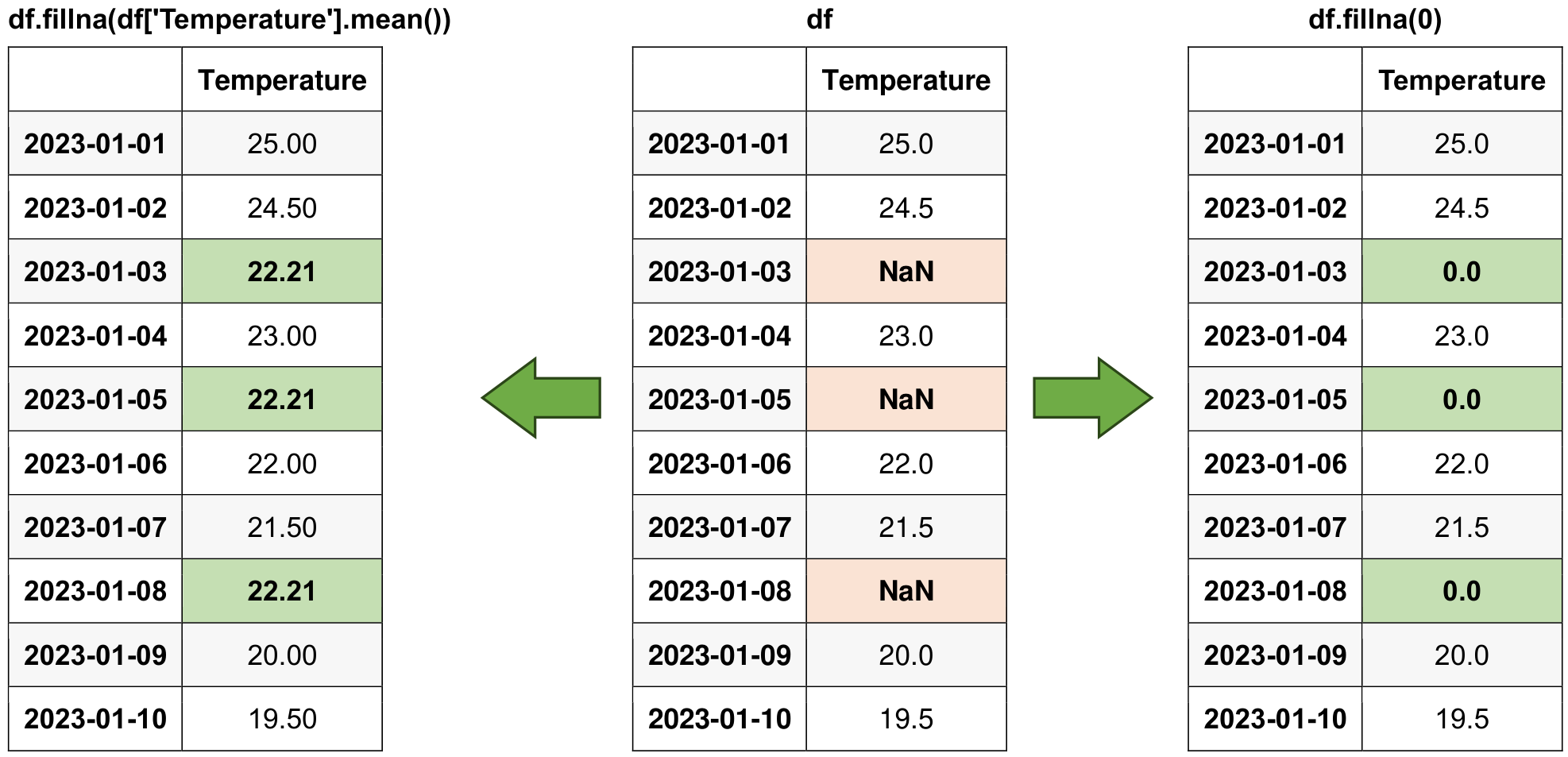
Fig. 5.11 Visual representation of the above example.#