9.1. Prologue: Statistical Metrics and Evaluation#
To utilize the content of this page optimally, I recommend consulting the relevant topic to gain a deeper understanding of specific subjects.
9.1.1. Training, Validation, and Test sets#
The process of partitioning a dataset into training, validation, and test sets is of paramount importance when it comes to evaluating predictive models effectively. This practice is elucidated and supported by the following explanations [Dangeti, 2017, Priddy and Keller, 2005]:
Training Set: The training set, constituting the largest portion of the dataset, serves as the bedrock for model development. Within this segment, machine learning algorithms glean insights from the data’s patterns. It is during this phase that the model is meticulously trained to recognize intricate relationships and make accurate predictions.
Validation Set: Following the training phase, the model’s performance is rigorously assessed using the validation set. This evaluation process is instrumental in fine-tuning the model’s hyperparameters and gauging its ability to generalize to new data. The validation set holds a critical role in preventing the model from overfitting or underfitting the training data.
Test Set: Different from the training set, the test set serves as an unbiased measure for evaluating the model’s performance on completely new and unseen data. Its primary function is to provide an estimate of how well the model is likely to perform when deployed in a real-world context.

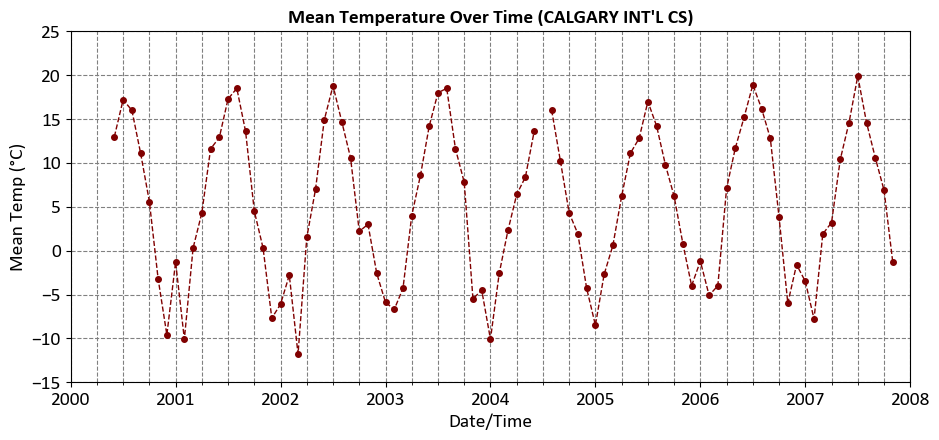
Fig. 9.2 The dataset is divided into three subsets: training, validation, and test, with an 80% allocation for training data, and 10% each for validation and testing.#
The partitioning of a dataset into these three subsets represents a fundamental and established practice in the development of robust machine learning models. This approach is widely embraced both within the academic sphere and the broader field of data analysis.
There are scenarios where only the training and test sets are used, and the validation set is omitted. The decision to exclude the validation set can be based on the specifics of the problem and the available data. Here are a few situations where using only the training and test sets might be appropriate:
Large Datasets: When you have a substantial amount of data, the training set can be sizeable enough to adequately train the model while still leaving a substantial portion for testing. In such cases, the need for a separate validation set is reduced.
K-Fold Cross-Validation: Instead of a fixed validation set, you can perform K-fold cross-validation using the training data. This involves splitting the training data into K subsets (folds) and iteratively using each fold as a validation set while training on the remaining data. This can provide a more robust assessment of model performance without the need for a dedicated validation set.
Limited Data Availability: In situations where data is scarce, allocating a portion to a validation set may significantly reduce the training data’s size, impacting the model’s ability to learn. In such cases, some practitioners choose to rely on the test set to evaluate the model’s performance.
Time Series Data: When dealing with time series data, it’s common to use only a training set and a test set. This is because the order of data points is critical, and random shuffling, as typically done with validation sets, can lead to data leakage. In time series analysis, the test set often represents future data points.
However, it’s essential to be cautious when omitting a validation set. The validation set is crucial for hyperparameter tuning and ensuring that the model generalizes well. If you choose to exclude it, you should be aware of the potential risks, such as overfitting or suboptimal model performance due to poor hyperparameter choices. The decision should be made based on a careful consideration of the specific problem, dataset size, and available resources.
9.1.2. Standard Error#
In statistics, the standard error (SE) is a way to measure how accurate an estimated value is, like the coefficients in a linear regression. It shows the average amount by which estimates can vary when we take multiple samples from the same group [Breiman, 2017, Scott, 2010].
The standard error (SE) is typically calculated using this formula:
Where:
\( s \) represents the sample standard deviation, which measures the variability of data points within the sample.
\( n \) is the number of data points (sample size).
This formula provides a straightforward way to compute the standard error, which quantifies the precision of an estimated value based on a given sample.
import pandas as pd
import matplotlib.pyplot as plt
# Set the matplotlib style using a custom style file
plt.style.use('../mystyle.mplstyle')
# Define the URL for the data
Link = 'https://climate.weather.gc.ca/climate_data/bulk_data_e.html?format=csv&stationID=27211&Year=2007&Month=1&Day=1&time=&timeframe=3&submit=Download+Data'
# Read the CSV data and select specific columns
df = pd.read_csv(Link, usecols=['Date/Time', 'Year', 'Month', 'Mean Temp (°C)'])
# Convert the 'Date/Time' column to datetime format and set it as the index
df['Date/Time'] = pd.to_datetime(df['Date/Time'])
df = df.set_index('Date/Time')
# Display the DataFrame
display(df)
# Create a figure and axes
fig, ax = plt.subplots(figsize=(9.5, 4.5))
# Create a line plot for 'Mean Temp (°C)'
df['Mean Temp (°C)'].plot(ax=ax, kind='line', color='Maroon', marker='.',
linestyle='--', linewidth=1,
title="""Mean Temperature Over Time (CALGARY INT'L CS)""",
xlabel='Date/Time', ylabel='Mean Temp (°C)',
xlim=['2000-01-01', '2008-01-01'], ylim=[-15, 25])
# Ensure the plot layout is tight
plt.tight_layout()
| Year | Month | Mean Temp (°C) | |
|---|---|---|---|
| Date/Time | |||
| 2000-06-01 | 2000 | 6 | 13.0 |
| 2000-07-01 | 2000 | 7 | 17.2 |
| 2000-08-01 | 2000 | 8 | 16.0 |
| 2000-09-01 | 2000 | 9 | 11.1 |
| 2000-10-01 | 2000 | 10 | 5.6 |
| ... | ... | ... | ... |
| 2007-07-01 | 2007 | 7 | 19.9 |
| 2007-08-01 | 2007 | 8 | 14.6 |
| 2007-09-01 | 2007 | 9 | 10.6 |
| 2007-10-01 | 2007 | 10 | 6.9 |
| 2007-11-01 | 2007 | 11 | -1.3 |
90 rows × 3 columns
import numpy as np
df['Month Name'] = df.index.month_name()
Standard_Error = df.groupby(['Month', 'Month Name'])['Mean Temp (°C)'].std(ddof=1)\
/np.sqrt(df.groupby(['Month'])['Mean Temp (°C)'].size())
Standard_Error = Standard_Error.to_frame('Standard Error')
display(Standard_Error)
| Standard Error | ||
|---|---|---|
| Month | Month Name | |
| 1 | January | 1.293705 |
| 2 | February | 1.107550 |
| 3 | March | 1.895717 |
| 4 | April | 0.756469 |
| 5 | May | 0.692378 |
| 6 | June | 0.337533 |
| 7 | July | 0.382349 |
| 8 | August | 0.588108 |
| 9 | September | 0.465003 |
| 10 | October | 0.641688 |
| 11 | November | 1.187885 |
| 12 | December | 1.062791 |
We also have the option to compute this using the scipy package:
from scipy import stats
Standard_Error = df.dropna().groupby(['Month', 'Month Name'])['Mean Temp (°C)']\
.agg(Mean_Temperature_C = 'mean',
SE = lambda x: stats.sem(x)).reset_index(drop = False)
display(Standard_Error)
| Month | Month Name | Mean_Temperature_C | SE | |
|---|---|---|---|---|
| 0 | 1 | January | -5.228571 | 1.293705 |
| 1 | 2 | February | -5.400000 | 1.107550 |
| 2 | 3 | March | -2.142857 | 1.895717 |
| 3 | 4 | April | 4.671429 | 0.756469 |
| 4 | 5 | May | 9.828571 | 0.692378 |
| 5 | 6 | June | 13.900000 | 0.337533 |
| 6 | 7 | July | 18.157143 | 0.408748 |
| 7 | 8 | August | 16.087500 | 0.588108 |
| 8 | 9 | September | 11.287500 | 0.465003 |
| 9 | 10 | October | 5.162500 | 0.641688 |
| 10 | 11 | November | -1.250000 | 1.187885 |
| 11 | 12 | December | -4.900000 | 1.062791 |
import matplotlib.pyplot as plt
import numpy as np
# Create a figure and axis
fig, ax = plt.subplots(figsize=(7.5, 6))
# Create the bar plot with error bars
ax.bar(x=Standard_Error['Month Name'],
height=Standard_Error.Mean_Temperature_C,
yerr= 1.96 * Standard_Error.SE,
capsize=5,
color='Bisque',
edgecolor='Tomato',
linewidth=2,
error_kw=dict(linewidth=2, ecolor='DarkRed'))
# Set labels and title
ax.set_xlabel('Month')
ax.set_ylabel('Mean Temperature (°C)')
ax.set_title('Monthly Mean Temperature with Standard Errors\nError bars demonstrate a 95% confidence interval', weight='bold')
# Set the Y-axis limits for better visualization
ax.set(ylim=[-10, 20])
# Rotate x-axis labels for better readability
ax.tick_params(axis='x', rotation=45)
# Add a grid for clarity
ax.grid(axis='y', linestyle='--', alpha=0.7)
# Add a horizontal line at y=0 for reference
ax.axhline(0, color='k', linewidth=1.5, linestyle='--')
# Customize the appearance
plt.tight_layout()
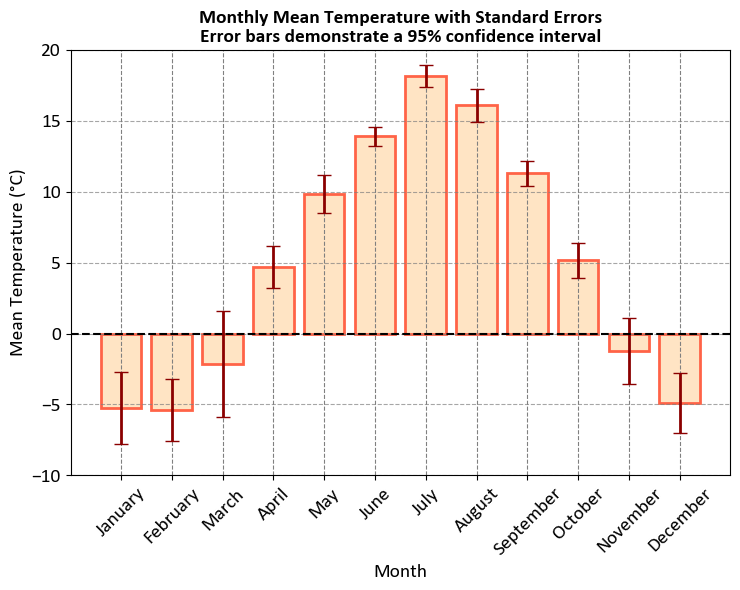
Let’s break down what it represents:
X-Axis (Month Name): The X-axis of the plot represents the months of the year, from January to December. Each month is labeled with its name.
Y-Axis (Mean Temperature in °C): The Y-axis represents the average (mean) temperature in degrees Celsius for each respective month. It shows the typical or average temperature for that month.
Bars: The blue bars on the plot represent the mean temperature for each month. The height of each bar indicates the average temperature for that specific month. For example, you can visually compare which months have higher or lower average temperatures.
Error Bars: The black vertical lines with caps extending from the top of the bars are error bars. These error bars represent the standard error associated with the mean temperature for each month. They show the level of uncertainty in the mean temperature estimate. Larger error bars indicate higher variability, meaning that the temperature data for that month varies more widely.
Note
If the error bar for a particular data point, such as March in your case, is longer than the actual bar, it typically means that the variability or uncertainty in that data point is relatively high compared to the actual value. This can happen for various reasons, such as:
Small Sample Size: If you have a small sample size for the data point (March in this case), the estimate of the mean (the actual bar) might have higher uncertainty, leading to a longer error bar.
Outliers: Outliers in the data can significantly affect the standard error and, consequently, the length of the error bars.
Heteroscedasticity: If the variability of data is not consistent across all data points, it can result in longer error bars for data points with higher variability.
Skewed Data: Data distributions that are not symmetric can lead to differences in the standard error and actual values, affecting the error bar length.
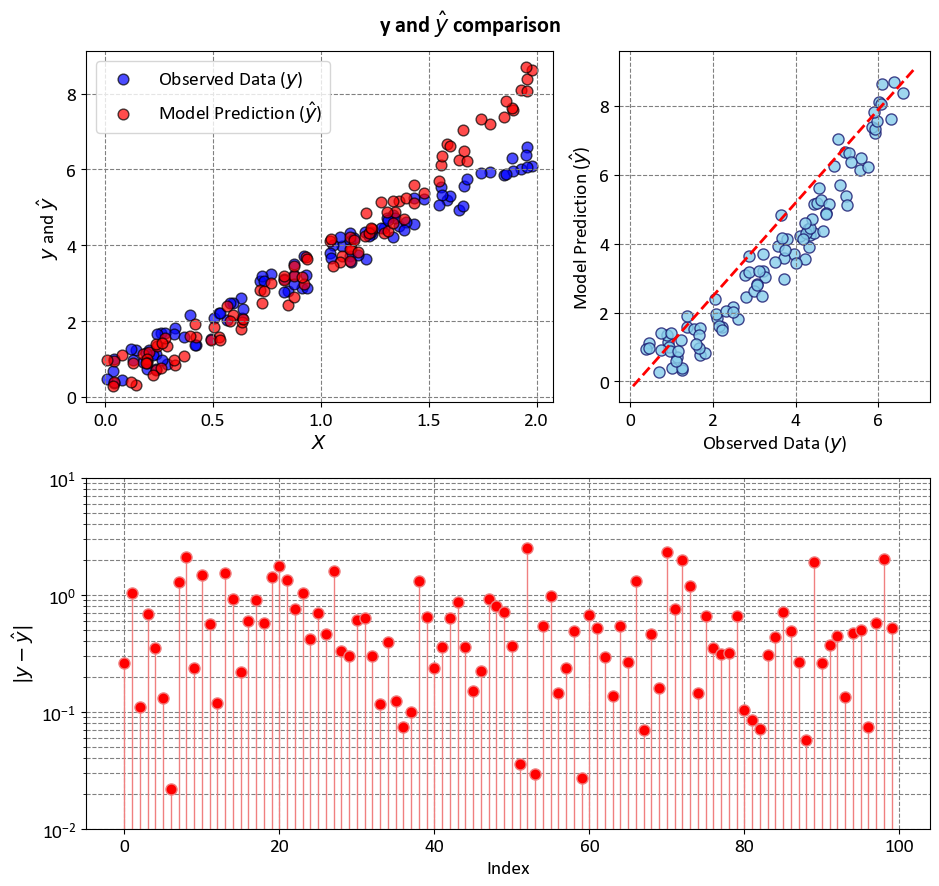
Example: In this example, we have two key variables, \(y\) and ‘y-hat,’ utilized to simulate and explain statistical metrics such as R-squared (\(R^2\)), Mean Squared Error (MSE), Mean Absolute Error (MAE), and more. \(y\) represents the observed data, which we aim to approximate, while \(\hat{y}\) is a constructed set of values used for this simulation. \(y\) serves as a representation of actual or observed data, although it’s important to note that in this case, we do not have a specific model generating \(y\) from ‘X’ or any real-world data. Instead, \(y\) is introduced as a reference point against which we can measure the performance of various statistical metrics. \(\hat{y}\) is a synthetic or hypothetical dataset, created for the purpose of this simulation. It is designed to emulate the values that a model might predict for \(y\) in a real-world scenario. The comparison between \(y\) and \(\hat{y}\) in this context provides a basis for understanding and evaluating statistical measures, shedding light on how well these metrics assess the relationship between observed and predicted data.
import numpy as np
import matplotlib.pyplot as plt
# Generate sample data
np.random.seed(0)
X = 2 * np.random.rand(100, 1)
y = 3 * X + np.random.rand(100, 1)
# Create a model or use any other method to make predictions
# In this example, we use a simple quadratic model for demonstration
y_hat = 1 * X**2 + 2 * X + np.random.rand(100, 1)
# =============================================================================
# Figure
# =============================================================================
fig, ax = plt.subplots(2, 2, figsize=(9.5, 9), gridspec_kw={'width_ratios': [.6, .4]})
ax = ax.ravel()
# Plot the data points and model predictions with enhanced styling
ax[0].scatter(X, y, c='blue', edgecolor='k', s=60,
alpha=0.7, label=r'Observed Data ($y$)')
ax[0].scatter(X, y_hat, c='red', edgecolor='k', s=60,
alpha=0.7, label=r'Model Prediction ($\hat{y}$)')
ax[0].set(xlabel=r'$X$', ylabel=r'$y$ and $\hat{y}$')
ax[0].legend(loc='upper left')
_ = ax[1].scatter(y, y_hat, facecolors='SkyBlue', edgecolors='MidnightBlue', alpha=0.8)
_ = ax[1].plot([ax[1].get_xlim()[0], ax[1].get_xlim()[1]],
[ax[1].get_ylim()[0], ax[1].get_ylim()[1]], '--r', linewidth=2)
_ = ax[1].set(xlabel=r'Observed Data ($y$)',
ylabel=r'Model Prediction ($\hat{y}$)')
gs = ax[2].get_gridspec()
for i in range(2, 4):
ax[i].remove()
ax3 = fig.add_subplot(gs[1, :])
markerline, _, _ = ax3.stem(np.arange(y.shape[0]), abs(y - y_hat),
linefmt='LightCoral', markerfmt='o')
_ = markerline.set_markerfacecolor('red')
_ = ax3.set(aspect='auto', xlabel='Index',
ylabel=r'$|y - \hat{y}|$',
yscale='log',
ylim=[1e-2, 1e1])
_ = fig.suptitle(r'y and $\hat{y}$ comparison', weight='bold', fontsize=16)
plt.tight_layout()
9.1.3. R-squared Statistic#
The R-squared statistic, symbolized as \(R^2\), is a valuable metric used in linear regression analysis to gauge the proportion of the total variability observed in the dependent variable (\(Y\)) that can be explained by the independent variable(s) (\(X\)) included in the model. It takes values within the range of 0 to 1, where a value of 1 indicates that the model perfectly accounts for the variability in the dependent variable, while a value of 0 suggests that the model fails to explain any of the observed variability [Powers, 2011, Scott, 2010, scikit-learn Developers, 2023].
The formula for calculating \(R^2\) is expressed as:
Here are the components in the formula:
\(n\) represents the number of data points in the dataset.
\(y_i\) signifies the actual value of the dependent variable for the \(i\)-th data point.
\(\hat{y}_i\) corresponds to the predicted value of the dependent variable for the \(i\)-th data point based on the regression model.
\(\bar{y}\) denotes the mean value of the dependent variable.
\(R^2\) is an essential tool in assessing the goodness of fit of a linear regression model. It quantifies how well the model’s predictions align with the actual data. A high \(R^2\) value implies that a substantial proportion of the variability in the dependent variable is captured by the model, indicating a better fit. Conversely, a low \(R^2\) suggests that the model is not effectively explaining the variability in the dependent variable, and improvements may be necessary.
R-squared can also be expressed as the square of the correlation coefficient, which measures the strength and direction of the linear relationship between two variables. The correlation coefficient, or \(r\), is a number between -1 and 1, where -1 means a perfect negative linear relationship, 0 means no linear relationship, and 1 means a perfect positive linear relationship. The formula for R-squared as the square of the correlation coefficient is:
where \(r\) is the correlation coefficient and is computed as:
where \(x_{i}\)and \(y_{i}\) are the values of the predictor and outcome variables, respectively, and \(N\) is the number of data points.
\(R^2\) has important uses, but it’s essential to complement its interpretation with other evaluation techniques, especially when working with complex models or in the presence of multicollinearity or heteroscedasticity. Combining \(R^2\) with domain knowledge and diagnostic tests ensures a comprehensive understanding of the model’s performance.
Remark
R-squared can also be negative, which means that the model fits the data even worse than a horizontal line. A horizontal line is the simplest model that uses the mean of the dependent variable as a constant prediction for all values of the independent variable.
There are two scenarios that can lead to a negative R-squared:
The model does not have an intercept term. This means that the model forces the regression line to go through the origin, which may not be appropriate for the data. For example, if the data has a positive mean, then a model without an intercept will always underestimate the dependent variable, resulting in a large RSS and a negative R-squared.
The model has a very steep slope that does not match the trend of the data. This means that the model is very sensitive to small changes in the independent variable, and may overestimate or underestimate the dependent variable by a large amount, resulting in a large RSS and a negative R-squared.
A negative R-squared implies that the model is not suitable for the data, and that some other model should be used instead. A negative R-squared also indicates that the model’s assumptions are violated, such as linearity, homoscedasticity, independence, and normality. Therefore, it is important to check the model’s diagnostics and perform appropriate transformations or adjustments before interpreting the R-squared value.
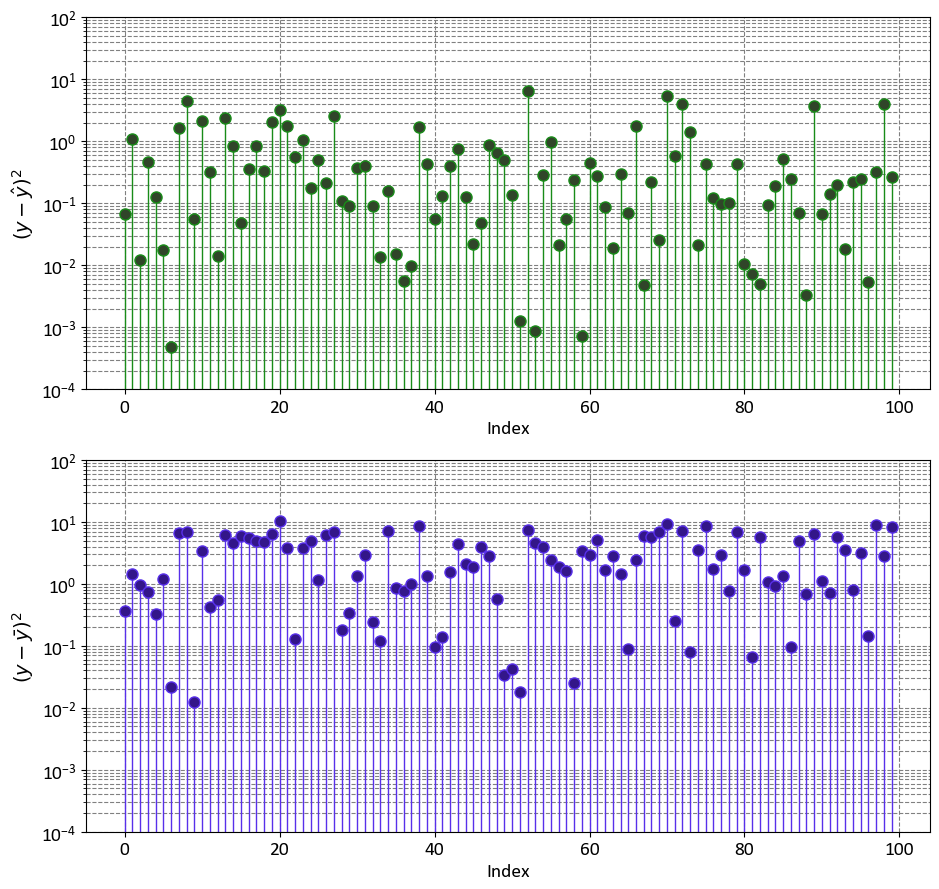
import numpy as np
import matplotlib.pyplot as plt
fig, ax = plt.subplots(2, 1, figsize=(9.5, 9))
ax = ax.ravel()
y_bar = np.mean(y)
markerline, _, _ = ax[0].stem(np.arange(y.shape[0]), (y - y_hat)**2,
linefmt='#198c19', markerfmt='o')
_ = markerline.set_markerfacecolor('#304529')
_ = ax[0].set(aspect='auto', xlabel='Index',
ylabel=r'$(y - \hat{y})^2$',
yscale='log',
ylim=[1e-4, 1e2])
markerline, _, _ = ax[1].stem(np.arange(y.shape[0]), (y - y_bar)**2,
linefmt='#5830ea', markerfmt='o')
_ = markerline.set_markerfacecolor('#331689')
_ = ax[1].set(aspect='auto', xlabel='Index',
ylabel=r'$(y - \bar{y})^2$',
yscale='log',
ylim=[1e-4, 1e2])
plt.tight_layout()
import numpy as np
def r2_score(y, y_hat):
# the mean of y
y_bar = np.mean(y)
# Sum of Squares Error
SSE = np.sum((y - y_hat)**2)
# Total Sum of Squares
SST = np.sum((y - y_bar)**2)
return 1 - (SSE / SST)
# Calculate R-squared
r_squared = r2_score(y, y_hat)
print(f'R-squared = {r_squared:.4f}')
R-squared = 0.7726
Using sklearn’s built-in r2_score:
from sklearn.metrics import r2_score
r_squared = r2_score(y, y_hat)
print(f'R-squared = {r_squared:.4f}')
R-squared = 0.7726
9.1.4. Mean Squared Error (MSE)#
The Mean Squared Error (MSE) is a fundamental metric used to quantify the goodness of fit of a regression model by measuring the average squared difference between the predicted values and the actual values of the dependent variable. It provides a measure of how well the model’s predictions align with the observed data [Powers, 2011, Scott, 2010, scikit-learn Developers, 2023].
Mathematically, the MSE is calculated using the following formula:
Here are the components in the formula:
\( n \) represents the number of data points in the dataset.
\( y_i \) signifies the actual value of the dependent variable for the \( i \)-th data point.
\( \hat{y}_i \) corresponds to the predicted value of the dependent variable for the \( i \)-th data point based on the regression model.
Interpreting the MSE:
The MSE measures the average squared difference between the predicted and actual values.
A lower MSE indicates that the model’s predictions are closer to the actual values, implying a better fit.
A higher MSE suggests that the model’s predictions deviate more from the actual values, indicating a poorer fit.
MSE is commonly used as a loss function to assess the performance of regression models during training. It plays a crucial role in model selection and comparison, helping to identify the model that provides the best balance between predictive accuracy and generalization.
It’s important to note that while MSE is a valuable metric for evaluating model performance, it should be interpreted in conjunction with other metrics and diagnostic tools to ensure a comprehensive understanding of the model’s strengths and limitations.
Example: Considering the data from the previous instance, we have
import numpy as np
import matplotlib.pyplot as plt
fig, ax = plt.subplots(1, 1, figsize=(9.5, 4.5))
y_bar = np.mean(y)
markerline, _, _ = ax.stem(np.arange(y.shape[0]), ((y - y_hat)**2)/len(y),
linefmt='#e483b3', markerfmt='o')
_ = markerline.set_markerfacecolor('#a94375')
_ = ax.set(aspect='auto', xlabel='Index',
ylabel=r'$\dfrac{(y - \hat{y})^2}{n}$',
yscale='log',
ylim=[1e-5, 1e-1])
plt.tight_layout()
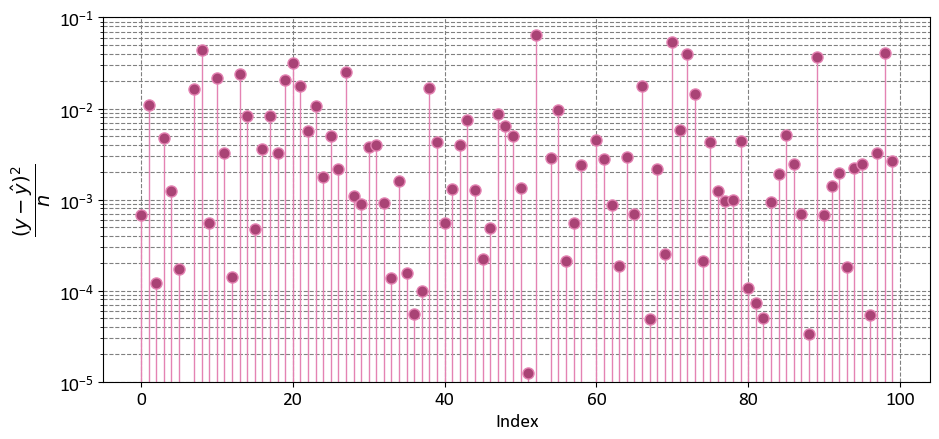
import numpy as np
def MSE_score(y, y_hat):
# Sum of Squares Error
SSE = np.sum((y - y_hat)**2)
return SSE/len(y)
# Calculate the Mean Squared Error to assess the goodness of fit
mse = MSE_score(y, y_hat)
print(f'R-squared = {mse:.4f}')
R-squared = 0.6836
Using sklearn’s built-in mean_squared_error:
from sklearn.metrics import mean_squared_error
# Calculate the Mean Squared Error to assess the goodness of fit
mse = mean_squared_error(y, y_hat)
print(f'R-squared = {mse:.4f}')
R-squared = 0.6836
9.1.5. Mean Absolute Error (MAE)#
The Mean Absolute Error (MAE) is a fundamental metric used in regression analysis to assess the accuracy of a predictive model by measuring the average absolute differences between the predicted values and the actual values of the dependent variable. It provides insight into how closely the model’s predictions align with the observed data [Powers, 2011, Scott, 2010, scikit-learn Developers, 2023].
Mathematically, the MAE is calculated as follows:
Here are the components in the formula:
\( n \) represents the number of data points in the dataset.
\( y_i \) denotes the actual value of the dependent variable for the \( i \)-th data point.
\( \hat{y}_i \) represents the predicted value of the dependent variable for the \( i \)-th data point based on the regression model.
Interpreting the MAE:
The MAE measures the average absolute difference between the predicted and actual values.
A lower MAE indicates that the model’s predictions are closer to the actual values, suggesting a better fit.
A higher MAE implies that the model’s predictions have larger absolute differences from the actual values, indicating a poorer fit.
MAE is often used in combination with other metrics to evaluate the performance of regression models, especially when dealing with outliers or when you want to penalize large prediction errors linearly. It provides valuable insights into the model’s predictive accuracy and is a useful tool for model selection and comparison.
import numpy as np
import matplotlib.pyplot as plt
fig, ax = plt.subplots(1, 1, figsize=(9.5, 4.5))
y_bar = np.mean(y)
markerline, _, _ = ax.stem(np.arange(y.shape[0]), (abs(y - y_hat)/len(y)),
linefmt='#d45353', markerfmt='o')
_ = markerline.set_markerfacecolor('#7f1717')
_ = ax.set(aspect='auto', xlabel='Index',
ylabel=r'$\dfrac{|y - \hat{y}|}{n}$',
yscale='log',
ylim=[1e-5, 1e-1])
plt.tight_layout()
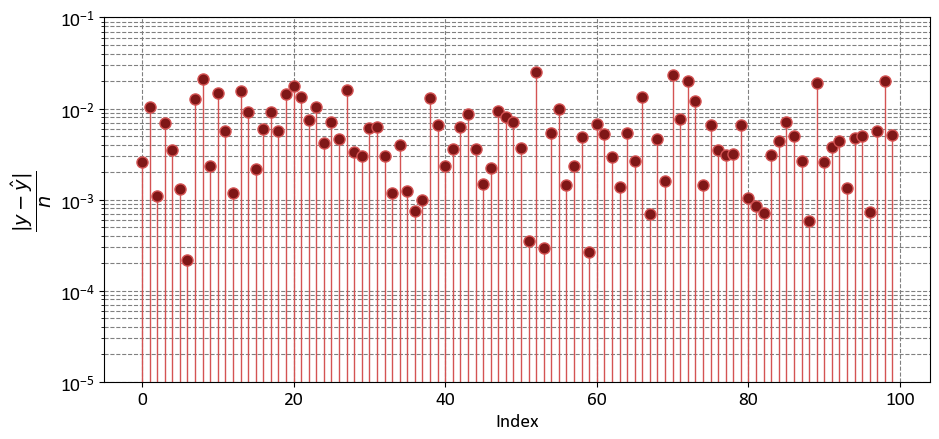
import numpy as np
def MAE_score(y, y_hat):
# Sum of Squares Error
SSE = np.sum(abs(y - y_hat))
return SSE/len(y)
# Calculate the Mean Absolute Error to assess the goodness of fit
mae = MAE_score(y, y_hat)
print(f'MAE = {mae:.4f}')
MAE = 0.6119
Using sklearn’s built-in mean_absolute_error:
from sklearn.metrics import mean_absolute_error
# Calculate the Mean Absolute Error to assess the goodness of fit
mae = mean_absolute_error(y, y_hat)
print(f'MAE = {mae:.4f}')
MAE = 0.6119
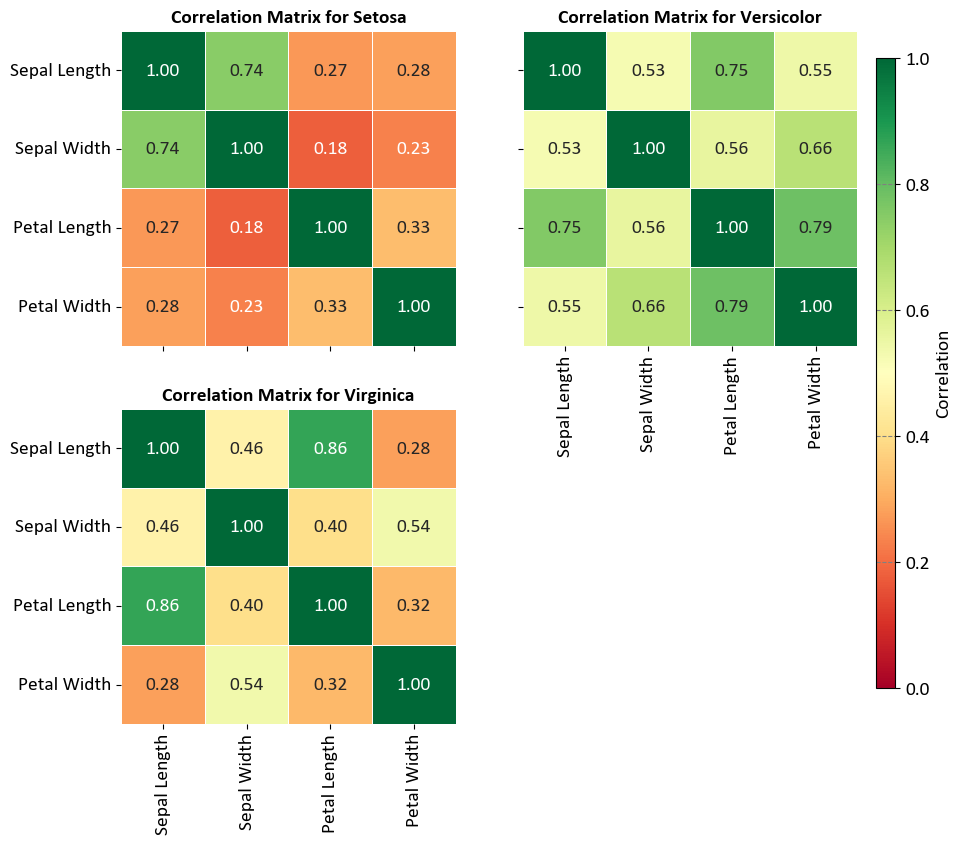
9.1.6. Correlation Matrix#
The correlation matrix is a square matrix that displays the correlations between different variables (parameters) in a given dataset. Each element in the matrix represents the correlation coefficient between two variables. The correlation coefficient measures the strength and direction of the linear relationship between two variables. It ranges from -1 to +1, with -1 indicating a perfect negative linear relationship, +1 indicating a perfect positive linear relationship, and 0 indicating no linear relationship [Powers, 2011, Scott, 2010, scikit-learn Developers, 2023].
The correlation coefficient between two variables \(X\) and \(Y\) can be calculated using the formula:
where:
\(n\) is the number of data points in the dataset.
\(x_i\) and \(y_i\) are the values of the \(X\) and \(Y\) variables, respectively, for the \(i\)th data point.
\(\bar{x}\) and \(\bar{y}\) are the mean values of \(X\) and \(Y\) variables, respectively.
The correlation matrix provides a convenient way to visualize the relationships between multiple variables in a dataset. It helps identify patterns of association and potential multicollinearity (high correlation between predictor variables) in regression models. A positive correlation coefficient indicates that the variables tend to increase or decrease together, while a negative correlation coefficient indicates an inverse relationship. A correlation coefficient close to 0 suggests little or no linear relationship between the variables.
Example - Iris Flower Pair Plot: To demonstrate the concept of correlation, we’ll use the Iris dataset. The following code calculates and displays the correlation matrix for each Iris species:
import seaborn as sns
import matplotlib.pyplot as plt
# Load the Iris dataset and format column titles and species names
iris = sns.load_dataset('iris')
iris.columns = [x.replace('_', ' ').title() for x in iris.columns]
iris.Species = iris.Species.map(lambda x: x.title())
# Display the formatted dataset
display(iris)
# Create a 2x2 grid of subplots with shared axes
fig, axes = plt.subplots(2, 2, figsize=(9.5, 9), sharex=False, sharey=True)
axes = axes.ravel()
# Remove the last subplot
fig.delaxes(axes[-1])
# List of species (Using only the first three species)
species_list = iris['Species'].unique()[:3]
# Calculate and display the correlation matrices for each species
for i, (species, ax) in enumerate(zip(species_list, axes)):
# Extract data for the current species
subset = iris[iris['Species'] == species]
# Calculate the correlation matrix for the subset
correlation_matrix = subset.drop(columns=['Species']).corr()
# Create a heatmap for the correlation matrix on the respective subplot
sns.heatmap(correlation_matrix, ax=ax,
annot=True, fmt='.2f',
cmap='RdYlGn', linewidths=0.5, cbar=False,
vmin=0, vmax=1,
annot_kws={"fontsize": 14})
# Set title for the subplot with proper formatting
ax.set_title(f'Correlation Matrix for {species}', weight='bold')
# Disable grid lines
ax.grid(False)
plt.setp(axes[0].get_xticklabels(), visible=False)
# Add a single color bar outside the subplots
cax = fig.add_axes([0.92, 0.15, 0.02, 0.7]) # Define the position and size of the color bar
sm = plt.cm.ScalarMappable(cmap='RdYlGn')
sm.set_array([])
cbar = plt.colorbar(sm, ax=axes, cax=cax)
cbar.set_label('Correlation', rotation=90)
| Sepal Length | Sepal Width | Petal Length | Petal Width | Species | |
|---|---|---|---|---|---|
| 0 | 5.1 | 3.5 | 1.4 | 0.2 | Setosa |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 | Setosa |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 | Setosa |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 | Setosa |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 | Setosa |
| ... | ... | ... | ... | ... | ... |
| 145 | 6.7 | 3.0 | 5.2 | 2.3 | Virginica |
| 146 | 6.3 | 2.5 | 5.0 | 1.9 | Virginica |
| 147 | 6.5 | 3.0 | 5.2 | 2.0 | Virginica |
| 148 | 6.2 | 3.4 | 5.4 | 2.3 | Virginica |
| 149 | 5.9 | 3.0 | 5.1 | 1.8 | Virginica |
150 rows × 5 columns
# Import necessary libraries
from scipy import stats
import seaborn as sns
import matplotlib.pyplot as plt
# Create a 2x2 grid of subplots with shared axes
fig, axes = plt.subplots(2, 2, figsize=(9.5, 9))
ax = axes.ravel()
# Define species and corresponding variable pairs
species = ['Setosa', 'Versicolor', 'Versicolor', 'Virginica']
variables = [('Sepal Length', 'Sepal Width'), ('Petal Length', 'Sepal Length'),
('Petal Length', 'Petal Width'), ('Petal Length', 'Sepal Length')]
# Loop through species and variables
for i, spec in enumerate(species):
# Select subset of data for the current species
subset = iris[iris['Species'] == spec]
x_var, y_var = variables[i]
# Create a regression plot for the selected variables
sns.regplot(x=subset[x_var], y=subset[y_var], ci=None,
scatter_kws={'s': 40, 'fc' : '#7fbdd4', 'ec': '#335f8a'},
line_kws={'color': 'red'}, ax=ax[i])
# Calculate and display the Pearson correlation coefficient
corr = stats.pearsonr(subset[x_var], subset[y_var]).statistic
ax[i].set_title(f'{x_var} vs. {y_var} for {spec}. Corr = {corr:.3f}')
# Adjust subplot layout for better presentation
plt.tight_layout()
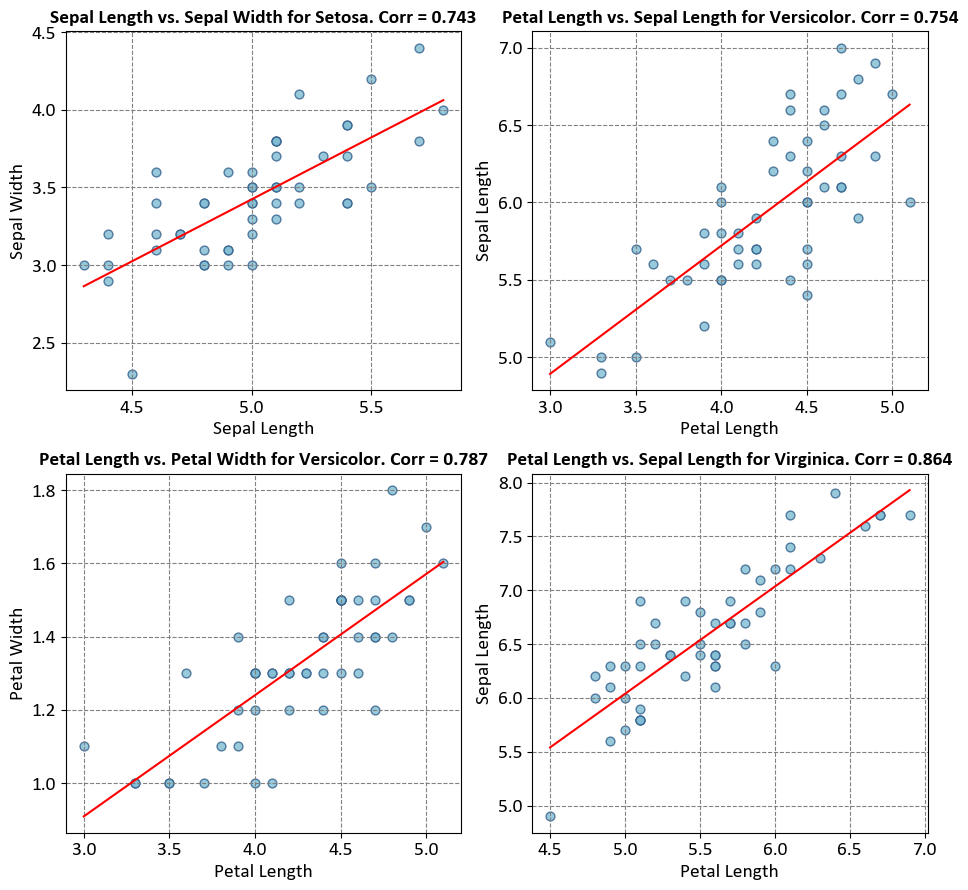
The relationship between the heatmap of linear correlation and the plot above lies in their shared objective of visualizing statistical relationships within a dataset. The plot presented here demonstrates scatterplots with regression lines, showcasing how two variables interact within different species of iris flowers. In contrast, a heatmap of linear correlation provides a comprehensive overview of the entire dataset, displaying the correlation coefficients between all pairs of variables in a matrix format. While the plot focuses on specific pairwise relationships within distinct species, the heatmap offers a broader perspective by highlighting the strength and direction of correlations across the entire dataset. Both visualization techniques are valuable tools in exploratory data analysis, with the scatterplot plot offering insights into individual relationships, and the heatmap providing a global view of correlation patterns within the data.
9.1.7. Confusion Matrix#
The confusion matrix is a fundamental tool used to evaluate the performance of classification algorithms by comparing their predictions against actual outcomes. It’s especially important for understanding the types of errors a model makes. To explain the math behind the confusion matrix, let’s consider a binary classification scenario, where there are two classes: “Positive” (P) and “Negative” (N). In this context, the confusion matrix is a 2x2 matrix with four entries [Powers, 2011, Scott, 2010, scikit-learn Developers, 2023]:
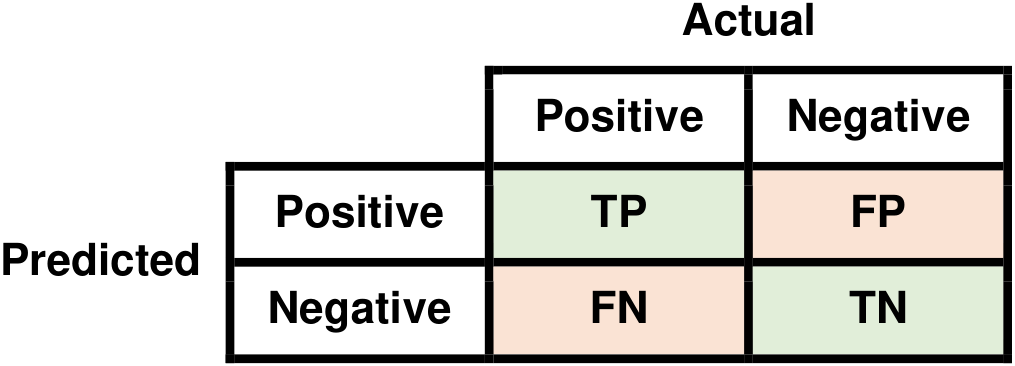
Fig. 9.3 Visual representation of a Confusion Matrix.#
How each of these terms is defined:
True Positives (TP): The number of instances that are actually positive (P) and are correctly predicted as positive by the classification algorithm.
False Positives (FP): The number of instances that are actually negative (N) but are incorrectly predicted as positive (P) by the algorithm.
True Negatives (TN): The number of instances that are actually negative (N) and are correctly predicted as negative by the algorithm.
False Negatives (FN): The number of instances that are actually positive (P) but are incorrectly predicted as negative (N) by the algorithm.
These elements provide valuable information about the performance of a classification model. They can be used to calculate various metrics like accuracy, precision, recall (sensitivity), specificity, and F1-score, which provide deeper insights into the model’s effectiveness in different aspects.
Keep in mind that the terms TP, FP, TN, and FN can have different interpretations depending on the context of the problem. For instance, in medical diagnostics, a false negative (FN) might mean failing to identify a disease in a patient, which could have significant consequences. Understanding the confusion matrix helps in understanding the strengths and weaknesses of a classification model in real-world applications.
Confusion Matrix Example in Environmental Classification: Water Pollution Detection (Fictional): Consider the following fictional example of a confusion matrix in the context of environmental classification, specifically applied to the detection of pollution in water samples:
Actual Polluted Water |
Actual Clean Water |
|
|---|---|---|
Predicted Polluted Water |
85 |
10 |
Predicted Clean Water |
15 |
120 |
In this confusion matrix:
“Clean Water” represents water samples that are truly clean and free from pollution.
“Polluted Water” represents water samples that are contaminated or polluted.
“Predicted Clean” represents water samples that a pollution detection system has correctly classified as clean.
“Predicted Polluted” represents water samples that a pollution detection system has correctly classified as polluted.
Now, let’s interpret the numbers:
There are 120 water samples that are truly clean (Clean Water) and were correctly classified as clean (Predicted Clean).
There are 15 water samples that are polluted (Polluted Water) but were incorrectly classified as clean (Predicted Clean).
There are 10 water samples that are truly clean (Clean Water) but were incorrectly classified as polluted (Predicted Polluted).
There are 85 water samples that are polluted (Polluted Water) and were correctly classified as polluted (Predicted Polluted).
In the context of the provided confusion matrix, which is used to evaluate the performance of a pollution detection system in water samples, we can interpret the terms TP (True Positives), FP (False Positives), TN (True Negatives), and FN (False Negatives) as follows:
True Positives (TP):
TP represents the cases where the pollution detection system correctly predicted that water samples were polluted (Predicted Polluted) and indeed, they were polluted (Actual Polluted Water).
In this example, there are 85 instances where the system correctly identified polluted water samples.
False Positives (FP):
FP represents the cases where the pollution detection system incorrectly predicted that water samples were polluted (Predicted Polluted), but in reality, they were clean (Actual Clean Water).
There are 10 instances where the system incorrectly classified clean water samples as polluted.
True Negatives (TN):
TN represents the cases where the pollution detection system correctly predicted that water samples were clean (Predicted Clean) and indeed, they were clean (Actual Clean Water).
In this example, there are 120 instances where the system correctly identified clean water samples.
False Negatives (FN):
FN represents the cases where the pollution detection system incorrectly predicted that water samples were clean (Predicted Clean), but in reality, they were polluted (Actual Polluted Water).
There are 15 instances where the system failed to detect pollution in water samples that were actually polluted.
9.1.8. Accuracy: Evaluating Correct Classifications#
Accuracy is a metric that quantifies the ratio of correctly classified instances to the total predictions made by a model. It’s determined using the elements of the confusion matrix [Powers, 2011, Scott, 2010, scikit-learn Developers, 2023]:
While commonly employed, accuracy may lead to misinterpretations, particularly in cases of imbalanced datasets. In such scenarios, where one class dominates, high accuracy can be achieved even when the model struggles to discern the minority class. Therefore, while accuracy provides an overall view of model performance, it’s advisable to complement it with additional metrics, especially when dealing with imbalanced data distributions.
Example: In the context of the Water Pollution Detection example, accuracy is computed using the following formula:
Where:
TP (True Positives) denotes instances where the pollution detection system correctly predicted “Polluted Water” (85).
TN (True Negatives) represents instances where the system correctly predicted “Clean Water” (120).
FP (False Positives) correspond to instances where the system incorrectly predicted “Polluted Water” when it was actually “Clean Water” (10).
FN (False Negatives) denote instances where the system incorrectly predicted “Clean Water” when it was actually “Polluted Water” (15).
Utilizing these values in the formula, we compute the accuracy as follows:
Thus, the accuracy of the pollution detection system in this example is approximately 0.8913 or 89.13%.
Example: In the context of the Water Pollution Detection example, accuracy is computed using the following formula:
Where:
TP (True Positives) denotes instances where the pollution detection system correctly predicted “Polluted Water” (85).
TN (True Negatives) represents instances where the system correctly predicted “Clean Water” (120).
FP (False Positives) correspond to instances where the system incorrectly predicted “Polluted Water” when it was actually “Clean Water” (10).
FN (False Negatives) denote instances where the system incorrectly predicted “Clean Water” when it was actually “Polluted Water” (15).
Utilizing these values in the formula, we compute the accuracy as follows:
Thus, the accuracy of the pollution detection system in this example is approximately 0.8913 or 89.13%.
9.1.9. Precision#
Precision is a metric that quantifies the accuracy of positive predictions made by a model, with particular emphasis on accounting for false positives. It is derived from the elements of the confusion matrix [Powers, 2011, Scott, 2010, scikit-learn Developers, 2023]::
Precision becomes particularly significant in situations where false positives carry substantial implications. In scenarios where a false positive prediction could lead to notable consequences, precision serves as a crucial measure of a model’s capacity to avoid such erroneous predictions.
Positive Predictive Value (PPV) or Precision: This is the proportion of positive results in statistics and diagnostic tests that are true positive results. It’s defined as:
A high PPV indicates that a positive test result is highly likely to be correct. The ideal value of the PPV, with a perfect test, is 1 (100%), and the worst possible value would be zero.
Negative Predictive Value (NPV): This is the proportion of negative results in statistics and diagnostic tests that are true negative results. It’s defined as:
A high NPV indicates that a negative test result is highly likely to be correct. With a perfect test, one which returns no false negatives, the value of the NPV is 1 (100%), and with a test which returns no true negatives the NPV value is zero.
Both PPV and NPV describe the performance of a diagnostic test or other statistical measure. They are not intrinsic to the test (unlike true positive rate and true negative rate); they also depend on the prevalence. Both PPV and NPV can be derived using Bayes’ theorem.
Example: In the context of the Water Pollution Detection example,
PPV or Precision for Polluted Water: \begin{equation*} \text{Precision} = \text{PPV} = \frac{TP}{TP + FP} = \frac{85}{85 + 10} = \frac{85}{95} \approx 0.8947 \end{equation*}
NPV for Clean Water: \begin{equation*} \text{NPV} = \frac{TN}{TN + FN} = \frac{120}{120 + 15} = \frac{120}{135} \approx 0.8889 \end{equation*}
9.1.10. Recall (Sensitivity or True Positive Rate)#
Recall, also known as sensitivity or the true positive rate (TPR), quantifies a model’s ability to correctly identify all positive instances, taking into account false negatives. It is calculated using the elements of the confusion matrix [Powers, 2011, Scott, 2010, scikit-learn Developers, 2023]:
Recall is particularly important in situations where avoiding false negatives is crucial. When the failure to detect positive cases can lead to significant consequences, recall serves as a key indicator of a model’s effectiveness in recognizing positive instances, ensuring that minimal instances are overlooked.
Specificity, Selectivity, or True Negative Rate (TNR): This is the ability of a test to correctly identify those instances without the condition. It’s also known as the True Negative Rate (TNR), i.e., the percentage of negative instances that are correctly identified as such. It’s defined as:
False Negative Rate (FNR): This is the proportion of positive instances which yield negative test outcomes with the test, i.e., the conditional probability of a negative test result given that the condition being looked for is present. It’s defined as:
A high FNR indicates that the model is not good at detecting positive cases.
False Positive Rate (FPR): This is the proportion of all negatives that still yield positive test outcomes, i.e., the conditional probability of a positive test result given an event that was not present. The false positive rate is calculated as the ratio between the number of negative events wrongly categorized as positive (false positives) and the total number of actual negative events (regardless of classification). It’s defined as:
A high FPR indicates that the model is not good at avoiding false alarms.
Both FNR and FPR describe the performance of a diagnostic test or other statistical measure. They are not intrinsic to the test (as PPV and NPV are); they depend also on the prevalence. Both FNR and FPR can be derived using Bayes’ theorem.
Example: In the context of the Water Pollution Detection example,
TPR or Recall for Polluted Water: \begin{equation*} \text{Recall} = \frac{TP}{TP + FN} = \frac{85}{85 + 15} = \frac{85}{100} = 0.85 \end{equation*}
TNR for Clean Water: \begin{equation*} \text{Recall} = \frac{TN}{TN + FP} = \frac{120}{120 + 10} = \frac{120}{130} \approx 0.9231 \end{equation*}
9.1.11. F1-Score#
The F1-Score presents a harmonious equilibrium between precision and recall, while accounting for both false positives and false negatives. It’s calculated using the confusion matrix elements [Powers, 2011, Scott, 2010, scikit-learn Developers, 2023]:
When a trade-off situation emerges between precision and recall, the F1-Score serves as a valuable indicator. In scenarios where achieving high precision might lower recall or vice versa, the F1-Score provides comprehensive insight into a model’s performance by considering the balance between these two vital aspects of prediction accuracy.
Example: In the context of the Water Pollution Detection example,
F1 Score for Polluted Water: \begin{equation} \text{F1 Score} = 2 \cdot \frac{\text{Precision} \cdot \text{Recall}}{\text{Precision} + \text{Recall}} = 2 \cdot \frac{0.8947 \cdot 0.85}{0.8947 + 0.85} \approx 0.8711 \end{equation}
9.1.12. Balanced Accuracy#
Balanced Accuracy is a metric that addresses the challenges posed by imbalanced datasets, where one class significantly outweighs the others. It calculates the average accuracy for each class, providing a more reliable measure of overall model performance [Powers, 2011, Scott, 2010, scikit-learn Developers, 2023].
The Balanced Accuracy is calculated as the average of the true positive rate (Recall) for each class:
Where:
\(N\) is the number of classes.
\(TP_i\) is the true positive count for class \(i\).
\(FN_i\) is the false negative count for class \(i\).
Balanced Accuracy takes into account the individual class performance, making it particularly useful for evaluating models in scenarios where class distribution is skewed. It offers a fairer assessment of how well a model performs across all classes, providing a more accurate representation of its effectiveness on imbalanced datasets.
In binary classification scenarios, Balanced Accuracy can be defined as the average of two key metrics: sensitivity (the true positive rate) and specificity (the true negative rate). Alternatively, it can be likened to the area under the Receiver Operating Characteristic (ROC) curve when using binary predictions instead of continuous scores. Mathematically, this can be expressed as:
This formula captures the balanced evaluation of a binary classification model’s ability to correctly identify both positive and negative instances while considering the trade-off between them.
Example: In the context of the Water Pollution Detection example,
9.1.13. Matthews Correlation Coefficient (MCC)#
The Matthews Correlation Coefficient (MCC) is a metric used to assess the quality of binary classification models. It takes into account true positives (TP), true negatives (TN), false positives (FP), and false negatives (FN) to provide a balanced evaluation of classification performance, especially when dealing with imbalanced datasets [Powers, 2011, Scott, 2010, scikit-learn Developers, 2023].
MCC ranges from -1 to +1, where:
+1 indicates perfect prediction.
0 indicates no better than random prediction.
-1 indicates perfect disagreement between predictions and actual classes.
Mathematically, MCC is calculated as:
\(TP \times TN\) term rewards correct positive and negative predictions.
\(FP \times FN\) term penalizes the count of false positive and false negative predictions.
The denominator normalizes the score, accounting for class distribution.
Key points about MCC:
Balanced Metric: MCC is suitable for imbalanced datasets because it considers TP, TN, FP, and FN, providing a balanced evaluation.
Symmetry: MCC is symmetric, meaning that swapping the positive and negative classes doesn’t affect the score.
Sensitive to Class Imbalance: Unlike accuracy, MCC isn’t easily misled by imbalanced data.
Usefulness: MCC helps identify how well the model’s predictions align with the actual classes, considering all four possible outcomes of binary classification.
Example: We also can calculate the Matthews Correlation Coefficient (MCC) for the Water Pollution Detection example as follows:
import math
def calculate_mcc(tp, tn, fp, fn):
numerator = (tp * tn) - (fp * fn)
denominator = math.sqrt((tp + fp) * (tp + fn) * (tn + fp) * (tn + fn))
mcc = numerator / denominator if denominator != 0 else 0.0
return mcc
mcc = calculate_mcc(tp=85, tn=120, fp=10, fn=15)
print(f"Matthews Correlation Coefficient (MCC): {mcc:.4f}")
Matthews Correlation Coefficient (MCC): 0.7783
9.1.14. Cohen’s Kappa#
Cohen’s Kappa, often referred to simply as Kappa, is a statistic used to measure the level of agreement between two raters or evaluators, especially in situations involving categorical data or classification tasks. It’s particularly useful when assessing the reliability or consistency of human judgments or the agreement between human judgments and machine predictions [Powers, 2011, Scott, 2010, scikit-learn Developers, 2023].
Kappa takes into account the agreement that could occur by chance and provides a normalized score that indicates the extent to which the observed agreement between raters or evaluators is beyond what could be expected by chance alone.
The formula for Cohen’s Kappa is as follows:
Where:
\( P_o \) is the observed proportion of agreement between the raters or evaluators.
\( P_e \) is the proportion of agreement expected by chance, calculated as the product of the marginal frequencies of the categories being rated.
Key points about Cohen’s Kappa:
Range of Values: Kappa values range from -1 to +1.
\( +1 \): Perfect agreement between raters.
\( 0 \): Agreement equivalent to chance.
\( -1 \): Complete disagreement between raters.
Adjustment for Chance: Kappa adjusts for agreement that could occur by random chance.
Interpretation: The interpretation of Kappa values varies, but typically:
\( 0.2 \) or less: Poor agreement.
\( 0.21 - 0.40 \): Fair agreement.
\( 0.41 - 0.60 \): Moderate agreement.
\( 0.61 - 0.80 \): Substantial agreement.
\( 0.81 - 1.00 \): Almost perfect agreement.
Considerations: Cohen’s Kappa is sensitive to the distribution of categories and can be affected by the prevalence of a particular category.
Cohen’s Kappa is a valuable tool in fields such as inter-rater reliability studies, medical diagnoses, and social sciences, where assessing agreement among raters is crucial. It provides insight into the reliability of judgments beyond raw agreement percentages and helps ensure the consistency and quality of human or machine-based evaluations.
In the context of a binary classification confusion matrix used in machine learning and statistics, Cohen’s Kappa formula can be expressed as follows:
Where:
TP represents the true positives.
FP represents the false positives.
TN represents the true negatives.
FN represents the false negatives.
Cohen’s Kappa is a metric used to assess the agreement between observed and expected classification results in binary classification scenarios. It quantifies the level of agreement beyond what would be expected by chance. Notably, in this context, Cohen’s Kappa is equivalent to the Heidke skill score used in Meteorology. This measure has a historical origin, as it was first introduced by Myrick Haskell Doolittle in 1888.
Example: In the Water Pollution Detection example, we can calculate Cohen’s Kappa as follows:
Total Number of Samples (\(N\)):
Observed Agreement (\(po\)):
Probabilities of Random Agreement (\(pe_{\text{polluted}}, pe_{\text{clean}}\)):
Cohen’s Kappa (\(\kappa\)):
def calculate_cohens_kappa(tp, tn, fp, fn):
# Calculate the total number of samples
total_samples = tp + tn + fp + fn
# Calculate observed agreement (po)
po = (tp + tn) / total_samples
# Calculate the probabilities of random agreement for each category
pe_polluted = ((tp + fp) / total_samples) * ((tp + fn) / total_samples)
pe_clean = ((tn + fp) / total_samples) * ((tn + fn) / total_samples)
# Calculate Cohen's Kappa
kappa = (po - (pe_polluted + pe_clean)) / (1 - (pe_polluted + pe_clean))
return kappa
# Define the values (you can replace these with your specific values)
tp = 85
tn = 120
fp = 10
fn = 15
# Calculate Cohen's Kappa using the function
kappa = calculate_cohens_kappa(tp, tn, fp, fn)
print(f"Cohen's Kappa: {kappa:.4f}")
Cohen's Kappa: 0.7776
Calculating Cohen’s Kappa for the Water Pollution Detection example using the binary formula:
def calculate_cohens_kappa_alt(tp, tn, fp, fn):
# Calculate Cohen's Kappa using the alternative formula
kappa = (2 * (tp * tn - fp * fn)) / ((tp + fp) * (fp + tn) + (tp + fn) * (fn + tn))
return kappa
# Define the values (you can replace these with your specific values)
tp = 85
tn = 120
fp = 10
fn = 15
# Calculate Cohen's Kappa using the alternative formula and the function
kappa = calculate_cohens_kappa_alt(tp, tn, fp, fn)
print(f"Cohen's Kappa: {kappa:.4f}")
Cohen's Kappa: 0.7776
9.1.15. Scikit-learn’s metrics#
Scikit-learn’s functions, such as sklearn.metrics.accuracy_score, sklearn.metrics.precision_score, sklearn.metrics.recall_score, and sklearn.metrics.f1_score, make use of these fundamental metrics for their computations. By interpreting these metrics within the context of the confusion matrix, practitioners can acquire a more profound insight into their model’s capabilities and limitations. This enhanced understanding empowers them to make informed decisions throughout the various stages of model development and deployment [Pedregosa et al., 2011, Powers, 2011, scikit-learn Developers, 2023].
Metric |
Description |
Formula or Usage |
|---|---|---|
|
Computes accuracy, the ratio of correctly predicted instances to the total instances. |
|
|
Calculates accuracy, considering imbalanced classes by averaging accuracy across classes. |
|
|
Measures the proportion of true positive predictions among all positive predictions. |
|
|
Computes the proportion of true positive predictions among actual positive instances. |
|
|
Balances precision and recall, combining them into a single score. |
|
|
Measures the proportion of true negative predictions among actual negative instances. |
Calculate sensitivity, then apply |
|
Calculates the likelihood of true negative predictions among all predicted negatives. |
|
|
Computes the proportion of false positive predictions among actual negative instances. |
|
|
Measures the rate of false negative predictions among actual positive instances. |
|
|
Incorporates true positives, true negatives, false positives, and false negatives into one value. |
|
|
Measures agreement between raters or evaluators while considering chance. |
|
… |
Additional metrics such as AUC-ROC, AUC-PR, log loss, etc. |
Various functions available in |
9.1.16. Additioal Information for statsmodels.api (Optional Content)#
The terms you’ve mentioned are statistical measures often included in regression analysis output or summary tables. They provide information about various aspects of the model’s goodness of fit, normality of residuals, and potential issues. Let’s delve into each of these metrics:
9.1.16.1. Standard Error and Coefficient Precision in Statistics#
In statistics, the standard error (SE) is a way to measure how accurate an estimated value is, like the coefficients in a linear regression. It shows the average amount by which estimates can vary when we take multiple samples from the same group [Breiman, 2017, Scott, 2010].
For a coefficient estimate \( \beta \) in a linear regression, you can find the standard error using this formula:
What each part means:
The standard error of estimate, denoted as \( S_e \), is computed as follows:
(9.28)#\[\begin{equation} S_e = \sqrt{\text{MSE}} = \sqrt\frac{{\sum_{i=1}^n({Y_i}-\hat{Y})^2}}{{n-2}} \end{equation}\]\( S_e \) is the standard error of estimate, representing the typical variability of data points around the regression line.
MSE stands for Mean Squared Error, which quantifies the average squared difference between observed values (\( Y_i \)) and predicted values (\( \hat{Y} \)).
The denominator \( (n-2) \) takes into account the loss of 2 degrees of freedom. This adjustment compensates for the estimation of both the intercept and the slope in the linear regression model, effectively reflecting the model’s complexity while calculating the standard error.
\( n \) is the number of data points in the dataset.
\( x_i \) is the value of the independent variable for the \( i \)th data point.
\( \bar{x} \) is the average value of the independent variable.
The standard error helps us understand how reliable our coefficient estimates are. Smaller standard errors mean more accurate coefficients that are less likely to be far off from the true population value.
Scientists often use the standard error to figure out confidence intervals for coefficient estimates. A confidence interval gives us a range of values where we can reasonably expect the true population value to be. This is how you usually calculate it:
The critical value is decided based on how sure we want to be and the t-statistic distribution.
9.1.16.2. t-value (\(t\)) and p-value (\(P>|t|\)) in Regression Analysis#
t-value (\(t\)) - Assessing Coefficient Significance: The t-value, also known as the t-statistic, is a critical statistic in regression analysis that helps us understand the importance of a coefficient estimate. It indicates how many standard errors the estimated coefficient is away from zero. The main goal of the t-value is to examine the hypothesis that the coefficient has no effect, essentially testing whether it is equal to zero within the model [Breiman, 2017, Scott, 2010].
Mathematically, the t-value is calculated as the ratio of the coefficient estimate to the standard error of that coefficient:
(9.30)#\[\begin{equation} t = \frac{\text{Coefficient Estimate}}{\text{Standard Error of the Coefficient}} \end{equation}\]The t-value plays a key role in determining the statistical significance of a coefficient. A large t-value suggests that the estimated coefficient significantly differs from zero. Conversely, a small t-value indicates that the coefficient might not be statistically distinguishable from zero, suggesting that the variable associated with the coefficient might not have a meaningful impact on the outcome.
The distribution of t-values follows a t-distribution, where the degrees of freedom are determined by the sample size and the number of predictor variables in the regression. A higher t-value, relative to the t-distribution with appropriate degrees of freedom, boosts confidence in the significance of the coefficient estimate. This makes the t-value an essential tool for hypothesis testing in statistical modeling.
p-value (\(P>|t|\)) - Evaluating Statistical Significance: The p-value associated with the t-value is a critical indicator of the statistical significance of a coefficient in regression analysis. It answers the question: “Is the observed effect (coefficient) statistically significant, or is it likely due to random chance?” The p-value’s calculation is grounded in the principles of the t-distribution, representing the probability of observing a t-value as extreme as the computed one, assuming that the null hypothesis (which assumes a coefficient of zero, implying no effect) is true [Breiman, 2017, Scott, 2010].
A small p-value, often set at a predetermined significance level (e.g., 0.05), suggests statistical significance. This implies that the variable associated with the coefficient likely has a genuine, non-zero impact on the dependent variable. The observed effect is unlikely to be solely a result of random chance. Conversely, a large p-value suggests that the observed effect could reasonably be attributed to random variability, rather than a real relationship between the variable and the dependent variable. In such cases, the effect is not considered statistically significant.
The p-value serves as a critical tool for hypothesis testing. Researchers and analysts frequently use the p-value to make informed decisions about whether to reject the null hypothesis, concluding coefficient significance, or to fail to reject it, considering the effect as non-significant. Selecting an appropriate significance level (alpha) beforehand helps establish the threshold for determining statistical significance, balancing the risk of Type I errors (incorrectly concluding significance) and Type II errors (incorrectly concluding non-significance). The p-value remains a valuable metric guiding these decisions in statistical modeling and hypothesis testing.
9.1.16.3. Omnibus Test#
Omnibus test is a measure of the overall goodness of fit of the regression model. It assesses whether the model’s residuals (the differences between actual and predicted values) are normally distributed. A significant Omnibus test suggests that the residuals do not follow a normal distribution, which might indicate a violation of one of the assumptions of linear regression.
How the Omnibus test works [Doornik and Hansen, 2008]:
Objective: The Omnibus test aims to determine whether the distribution of the residuals is symmetric and bell-shaped, as is the case with a normal distribution. If the residuals closely resemble a normal distribution, it indicates that the model’s assumptions are met and that the linear relationship between the independent variables and the dependent variable is a reasonable approximation.
Calculation: The test combines measures of skewness and kurtosis of the residuals to evaluate their departure from normality. Skewness assesses the symmetry of the distribution, while kurtosis examines the “tailedness” or peak of the distribution.
Hypotheses: The null hypothesis (\(H_0\)) of the Omnibus test is that the residuals are normally distributed. The alternative hypothesis (\(H_1\)) is that the residuals are not normally distributed.
Test Statistic: The Omnibus test statistic is often computed using the Chi-squared (\(\chi^2\)) distribution. It is calculated based on the skewness and kurtosis of the residuals and follows a Chi-squared distribution with degrees of freedom equal to 2.
Interpretation: The resulting test statistic is compared to a critical value from the Chi-squared distribution based on the chosen significance level (usually 0.05). If the calculated test statistic exceeds the critical value, the null hypothesis is rejected, indicating that the residuals do not follow a normal distribution. This suggests that the model might not be the best fit for the data, and further investigation or adjustments to the model might be necessary.
Prob(Omnibus)
“Prob(Omnibus)” is a statistical metric that is often included in the output of regression analysis, particularly when using software packages like statsmodels in Python. It is associated with the Omnibus test, which is a test for the normality of the residuals in a regression model [Kenett et al., 2023].
The Omnibus test assesses whether the distribution of the residuals follows a normal distribution. The “Prob(Omnibus)” value, also known as the p-value for the Omnibus test, indicates the probability of observing the calculated Omnibus test statistic (or a more extreme value) if the residuals were drawn from a truly normal distribution. In other words, it quantifies the evidence against the null hypothesis that the residuals are normally distributed.
How to interpret the “Prob(Omnibus)” value:
Low p-value (typically below 0.05): A low “Prob(Omnibus)” value suggests that the residuals significantly deviate from a normal distribution. In this case, you might question the assumption of normality and consider potential issues with the model. A low p-value indicates that you have evidence to reject the null hypothesis of normality.
High p-value (typically above 0.05): A high “Prob(Omnibus)” value indicates that there is not enough evidence to reject the null hypothesis of normality. This suggests that the residuals are reasonably consistent with a normal distribution, and the model’s assumption of normality might be valid.
Example:
import numpy as np
import statsmodels.api as sm
# Generate sample data
np.random.seed(0)
X = 2 * np.random.rand(100, 1)
y = 3 * X + np.random.rand(100, 1)
# Add a constant term (intercept) to the independent variable
X = sm.add_constant(X)
# Create a linear regression model
model = sm.OLS(y, X).fit()
# Perform the Omnibus Test for goodness of fit
omnibus_test = sm.stats.omni_normtest(model.resid)
# Display the test statistics and p-value
print(f"Omnibus Test Statistics: {omnibus_test.statistic:.4f}")
print(f"Omnibus Test p-value: {omnibus_test.pvalue:.4f}")
# Interpret the results
if omnibus_test.pvalue < 0.05:
print("The residuals are not normally distributed, indicating potential model issues.")
else:
print("The residuals are normally distributed, suggesting a better model fit.")
Omnibus Test Statistics: 19.2758
Omnibus Test p-value: 0.0001
The residuals are not normally distributed, indicating potential model issues.
We can also obtain this information by using print(model.summary()):
print(model.summary())
OLS Regression Results
==============================================================================
Dep. Variable: y R-squared: 0.975
Model: OLS Adj. R-squared: 0.974
Method: Least Squares F-statistic: 3766.
Date: Mon, 13 Jan 2025 Prob (F-statistic): 5.22e-80
Time: 12:20:31 Log-Likelihood: -13.196
No. Observations: 100 AIC: 30.39
Df Residuals: 98 BIC: 35.60
Df Model: 1
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
const 0.5581 0.054 10.417 0.000 0.452 0.664
x1 2.9683 0.048 61.365 0.000 2.872 3.064
==============================================================================
Omnibus: 19.276 Durbin-Watson: 2.031
Prob(Omnibus): 0.000 Jarque-Bera (JB): 5.354
Skew: -0.191 Prob(JB): 0.0688
Kurtosis: 1.933 Cond. No. 3.58
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
9.1.16.4. Durbin-Watson Statistic#
The Durbin-Watson statistic is a numerical measure used to detect the presence of autocorrelation (serial correlation) in the residuals of a regression model, particularly in time series or panel data analysis. Autocorrelation refers to the correlation between a variable and its lagged values. The Durbin-Watson statistic helps assess whether the residuals exhibit a pattern of dependence over time [Dufour and Dagenais, 1983].
How the Durbin-Watson statistic works:
Objective: The primary purpose of the Durbin-Watson statistic is to determine whether there is a significant correlation between the residuals of consecutive observations in a time series or panel data context. Autocorrelation in residuals can indicate that the model has not captured all relevant information, leading to omitted variables or incorrect model specification.
Calculation: The Durbin-Watson statistic is calculated using the differences between consecutive residuals. Specifically, it’s computed as the ratio of the sum of squared differences between consecutive residuals to the sum of squared residuals. Mathematically, the formula for the Durbin-Watson statistic (\(DW\)) is:
(9.31)#\[\begin{equation} DW = \frac{\sum_{t=2}^{n} (e_t - e_{t-1})^2}{\sum_{t=1}^{n} e_t^2} \end{equation}\]Where:
\( e_t \) is the residual at time \( t \).
\( n \) is the number of observations in the time series.
Interpretation: The Durbin-Watson statistic ranges from 0 to 4, with values closer to 2 indicating less autocorrelation. The statistic’s significance largely depends on its proximity to 2:
A Durbin-Watson statistic close to 2 (around 2) suggests that there is little or no autocorrelation present in the residuals, implying that the model’s assumptions are met.
A Durbin-Watson statistic significantly less than 2 (closer to 0) indicates positive autocorrelation, meaning that residuals tend to be positively correlated with their lagged values.
A Durbin-Watson statistic significantly greater than 2 (closer to 4) suggests negative autocorrelation, where residuals tend to be negatively correlated with their lagged values.
Rule of Thumb: Generally, a Durbin-Watson statistic value between 1.5 and 2.5 is often considered acceptable and indicative of minimal autocorrelation issues.
In summary, the Durbin-Watson statistic helps analysts identify the presence and nature of autocorrelation in the residuals of a time series or panel data regression model. It guides researchers in assessing the validity of the model assumptions and determining whether further adjustments or exploration are necessary.
Example:
import numpy as np
import statsmodels.api as sm
from statsmodels.stats.stattools import durbin_watson
# Generate sample data
np.random.seed(0)
X = 2 * np.random.rand(100, 1)
y = 3 * X + np.random.rand(100, 1)
# Add a constant term (intercept) to the independent variable
X = sm.add_constant(X)
# Create a linear regression model
model = sm.OLS(y, X).fit()
# Perform the Omnibus Test for goodness of fit
omnibus_test = sm.stats.omni_normtest(model.resid)
# Calculate the Durbin-Watson statistic
dw_statistic = durbin_watson(model.resid)
# Display the Durbin-Watson statistic
print(f"Durbin-Watson Statistic: {dw_statistic:.4f}")
# Interpret the results
if omnibus_test.pvalue < 0.05:
print("The residuals are not normally distributed, indicating potential model issues.")
else:
print("The residuals are normally distributed, suggesting a better model fit.")
if dw_statistic < 1.5:
print("Positive autocorrelation may be present in the residuals.")
elif dw_statistic > 2.5:
print("Negative autocorrelation may be present in the residuals.")
else:
print("No significant autocorrelation is detected in the residuals.")
Durbin-Watson Statistic: 2.0308
The residuals are not normally distributed, indicating potential model issues.
No significant autocorrelation is detected in the residuals.
We can also obtain this information by using print(model.summary()):
print(model.summary())
OLS Regression Results
==============================================================================
Dep. Variable: y R-squared: 0.975
Model: OLS Adj. R-squared: 0.974
Method: Least Squares F-statistic: 3766.
Date: Mon, 13 Jan 2025 Prob (F-statistic): 5.22e-80
Time: 12:20:31 Log-Likelihood: -13.196
No. Observations: 100 AIC: 30.39
Df Residuals: 98 BIC: 35.60
Df Model: 1
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
const 0.5581 0.054 10.417 0.000 0.452 0.664
x1 2.9683 0.048 61.365 0.000 2.872 3.064
==============================================================================
Omnibus: 19.276 Durbin-Watson: 2.031
Prob(Omnibus): 0.000 Jarque-Bera (JB): 5.354
Skew: -0.191 Prob(JB): 0.0688
Kurtosis: 1.933 Cond. No. 3.58
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
9.1.16.5. Jarque-Bera (JB) Test#
The Jarque-Bera (JB) test is a statistical test used to assess the normality of the residuals in a regression model. It evaluates whether the distribution of the residuals is symmetric and bell-shaped, resembling a normal distribution. The JB test is particularly important when dealing with linear regression models, as the validity of the normality assumption for the residuals is a key consideration [Nagakura, 2022].
How the Jarque-Bera test works:
Objective: The primary goal of the Jarque-Bera test is to determine whether the residuals of a regression model exhibit characteristics consistent with a normal distribution. A significant result indicates that the residuals deviate from normality, which can impact the reliability of statistical inference based on the model.
Calculation: The Jarque-Bera test relies on the skewness and kurtosis of the residuals. Skewness measures the symmetry of the distribution, while kurtosis gauges the “tailedness” of the distribution.
Hypotheses: The null hypothesis (\(H_0\)) of the Jarque-Bera test is that the residuals follow a normal distribution. The alternative hypothesis (\(H_1\)) is that the residuals do not follow a normal distribution.
Test Statistic: The test statistic for the Jarque-Bera test is calculated using the skewness and kurtosis of the residuals. It follows a Chi-squared (\(\chi^2\)) distribution with 2 degrees of freedom.
Interpretation: The calculated test statistic is compared to a critical value from the Chi-squared distribution, based on the chosen significance level (usually 0.05). If the calculated test statistic exceeds the critical value, the null hypothesis is rejected, indicating that the residuals do not follow a normal distribution. This suggests that the normality assumption for the residuals might not be met, which can affect the reliability of model inference.
Prob(JB): The “Prob(JB)” value, often reported alongside the JB test statistic, provides the probability associated with the JB test. It indicates the likelihood of observing the calculated JB test statistic (or a more extreme value) under the assumption of normality. A small “Prob(JB)” value indicates that the residuals deviate significantly from normality.
Prob(JB)
“Prob(JB)” is a statistical metric often found in regression analysis output or summary tables, particularly in the context of assessing the normality of residuals using the Jarque-Bera (JB) test.
The Jarque-Bera test evaluates whether the distribution of the residuals of a regression model is consistent with a normal distribution. The “Prob(JB)” value, also known as the p-value for the Jarque-Bera test, provides important information about the significance of the test result.
How to interpret the “Prob(JB)” value:
Low p-value (typically below 0.05): A low “Prob(JB)” value suggests that the residuals significantly deviate from a normal distribution. In other words, there is strong evidence against the null hypothesis that the residuals are normally distributed. This indicates a departure from normality and raises concerns about the model’s assumption.
High p-value (typically above 0.05): A high “Prob(JB)” value indicates that there is not enough evidence to reject the null hypothesis of normality. In this case, the residuals are consistent with a normal distribution, and the model’s assumption of normality might be valid.
import numpy as np
import statsmodels.api as sm
from statsmodels.stats.stattools import durbin_watson, jarque_bera
# Generate sample data
np.random.seed(0)
X = 2 * np.random.rand(100, 1)
y = 3 * X + np.random.rand(100, 1)
# Add a constant term (intercept) to the independent variable
X = sm.add_constant(X)
# Create a linear regression model
model = sm.OLS(y, X).fit()
# Perform the Omnibus Test for goodness of fit
omnibus_test = sm.stats.omni_normtest(model.resid)
# Calculate the Durbin-Watson statistic
dw_statistic = durbin_watson(model.resid)
# Perform the Jarque-Bera (JB) test for normality
jb_statistic, jb_p_value, _, _ = jarque_bera(model.resid)
# Display the JB test results
print(f"Jarque-Bera Statistic: {jb_statistic:.4f}")
print(f"Jarque-Bera p-value: {jb_p_value:.4f}")
# Interpret the results
if omnibus_test.pvalue < 0.05:
print("The residuals are not normally distributed, indicating potential model issues.")
else:
print("The residuals are normally distributed, suggesting a better model fit.")
if dw_statistic < 1.5:
print("Positive autocorrelation may be present in the residuals.")
elif dw_statistic > 2.5:
print("Negative autocorrelation may be present in the residuals.")
else:
print("No significant autocorrelation is detected in the residuals.")
if jb_p_value < 0.05:
print("The residuals do not follow a normal distribution, suggesting non-normality.")
else:
print("The residuals follow a normal distribution, indicating normality.")
Jarque-Bera Statistic: 5.3540
Jarque-Bera p-value: 0.0688
The residuals are not normally distributed, indicating potential model issues.
No significant autocorrelation is detected in the residuals.
The residuals follow a normal distribution, indicating normality.
We can also obtain this information by using print(model.summary()):
print(model.summary())
OLS Regression Results
==============================================================================
Dep. Variable: y R-squared: 0.975
Model: OLS Adj. R-squared: 0.974
Method: Least Squares F-statistic: 3766.
Date: Mon, 13 Jan 2025 Prob (F-statistic): 5.22e-80
Time: 12:20:31 Log-Likelihood: -13.196
No. Observations: 100 AIC: 30.39
Df Residuals: 98 BIC: 35.60
Df Model: 1
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
const 0.5581 0.054 10.417 0.000 0.452 0.664
x1 2.9683 0.048 61.365 0.000 2.872 3.064
==============================================================================
Omnibus: 19.276 Durbin-Watson: 2.031
Prob(Omnibus): 0.000 Jarque-Bera (JB): 5.354
Skew: -0.191 Prob(JB): 0.0688
Kurtosis: 1.933 Cond. No. 3.58
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
9.1.16.6. Skewness#
Skewness is a statistical measure that quantifies the asymmetry of the probability distribution of a dataset or variable. It indicates the degree to which the data’s distribution is skewed or “lopsided.” In the context of regression analysis, skewness often refers to the skewness of the residuals of a model.
How skewness works:
Symmetry and Skewness: In a symmetric distribution, the left and right sides of the distribution are mirror images of each other. For a perfectly symmetric distribution, the mean, median, and mode coincide at the center of the distribution. Skewness measures the departure from this symmetry.
Positive Skewness: Positive skewness occurs when the distribution’s tail is longer on the right side (positively skewed). This means that the distribution is stretched out to the right, and the majority of data points are concentrated on the left side. The mean tends to be greater than the median in a positively skewed distribution.
Negative Skewness: Negative skewness occurs when the distribution’s tail is longer on the left side (negatively skewed). In this case, the distribution is stretched out to the left, and the majority of data points are concentrated on the right side. The mean tends to be less than the median in a negatively skewed distribution.
Calculation of Skewness: The skewness of a dataset \(X\) can be calculated using the formula:
(9.32)#\[\begin{equation} \text{Skewness}(X) = \frac{\sum_{i=1}^{n} (x_i - \bar{x})^3}{n \cdot s^3} \end{equation}\]Where:
\( n \) is the number of data points in the dataset.
\( x_i \) represents each data point.
\( \bar{x} \) is the mean of the dataset.
\( s \) is the standard deviation of the dataset.
Interpretation: Skewness values can be positive, negative, or close to zero. A skewness of 0 indicates perfect symmetry. Larger positive or negative skewness values indicate increasing levels of skewness. Skewness values are dimensionless, making them suitable for comparing the skewness of different datasets.
In the context of regression analysis, examining the skewness of the residuals is important because normally distributed residuals are a common assumption of linear regression models. Skewed residuals could suggest a lack of fit of the model to the data, leading to potential biases in the coefficient estimates and statistical inferences. Addressing skewness might involve transformations of the dependent or independent variables to achieve better model performance.
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
from scipy.stats import skew
import warnings
warnings.simplefilter(action="ignore", category=FutureWarning)
# Sample data
data = np.array([12, 14, 15, 16, 18, 20, 22, 23, 24, 26, 28, 30, 35, 40])
# Calculate skewness
skewness = skew(data)
# Create figure and axis
fig, ax = plt.subplots(figsize=(6, 4))
# Create a KDE plot
sns.kdeplot(data, fill=True, color="blue", ax=ax)
# Add labels and title
ax.set(xlabel = "Values", ylabel = "Density", title = f"Skewness: {skewness:.2f}")
# Display the plot
plt.tight_layout()

Example:
import numpy as np
import statsmodels.api as sm
from scipy.stats import skew
# Generate sample data
np.random.seed(0)
X = 2 * np.random.rand(100, 1)
y = 3 * X + np.random.rand(100, 1)
# Add a constant term (intercept) to the independent variable
X = sm.add_constant(X)
# Create a linear regression model
model = sm.OLS(y, X).fit()
# Calculate the skewness of residuals
residual_skew = skew(model.resid)
# Display the skewness of residuals
print(f"Skewness of Residuals: {residual_skew:.4f}")
Skewness of Residuals: -0.1913
We can also obtain this information by using print(model.summary()):
print(model.summary())
OLS Regression Results
==============================================================================
Dep. Variable: y R-squared: 0.975
Model: OLS Adj. R-squared: 0.974
Method: Least Squares F-statistic: 3766.
Date: Mon, 13 Jan 2025 Prob (F-statistic): 5.22e-80
Time: 12:20:31 Log-Likelihood: -13.196
No. Observations: 100 AIC: 30.39
Df Residuals: 98 BIC: 35.60
Df Model: 1
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
const 0.5581 0.054 10.417 0.000 0.452 0.664
x1 2.9683 0.048 61.365 0.000 2.872 3.064
==============================================================================
Omnibus: 19.276 Durbin-Watson: 2.031
Prob(Omnibus): 0.000 Jarque-Bera (JB): 5.354
Skew: -0.191 Prob(JB): 0.0688
Kurtosis: 1.933 Cond. No. 3.58
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
9.1.16.7. Kurtosis#
Kurtosis is a statistical measure that quantifies the “tailedness” or the extent to which the tails of a probability distribution differ from those of a normal distribution. In the context of regression analysis or statistics in general, kurtosis provides information about the shape of the distribution of a dataset or variable [Norman and Streiner, 2008].
How kurtosis works:
Kurtosis and Distribution Shape: Kurtosis focuses on the tails of a distribution. A normal distribution has a kurtosis of 3, and distributions with higher kurtosis have heavier tails, indicating more extreme values than the tails of a normal distribution. Distributions with lower kurtosis have lighter tails, suggesting fewer extreme values.
Leptokurtic Distribution: A distribution with positive kurtosis (greater than 3) is called leptokurtic. Leptokurtic distributions have heavy tails and a peak that is higher and sharper than that of a normal distribution. This means that extreme values are more likely to occur in a leptokurtic distribution.
Platykurtic Distribution: A distribution with negative kurtosis (less than 3) is called platykurtic. Platykurtic distributions have lighter tails and a peak that is lower and flatter than that of a normal distribution. Extreme values are less likely to occur in a platykurtic distribution.
Mesokurtic Distribution: A distribution with kurtosis equal to 3 is called mesokurtic. A mesokurtic distribution has tails and a peak that are similar to those of a normal distribution.
Calculation of Kurtosis: The kurtosis of a dataset \(X\) can be calculated using the formula:
(9.33)#\[\begin{equation} \text{Kurtosis}(X) = \frac{\sum_{i=1}^{n} (x_i - \bar{x})^4}{n \cdot s^4} \end{equation}\]Where:
\( n \) is the number of data points in the dataset.
\( x_i \) represents each data point.
\( \bar{x} \) is the mean of the dataset.
\( s \) is the standard deviation of the dataset.
Interpretation: Positive kurtosis indicates heavier tails and a more peaked distribution, while negative kurtosis indicates lighter tails and a flatter distribution. The closer the kurtosis is to 3, the more similar the distribution is to a normal distribution.
In the context of regression analysis, examining the kurtosis of the residuals can provide insights into the distributional characteristics of the model’s errors. Kurtosis, along with other diagnostic metrics, helps analysts evaluate the normality assumption and make informed decisions about potential model adjustments or transformations.
Example:
import numpy as np
import statsmodels.api as sm
from scipy.stats import skew, kurtosis
# Generate sample data
np.random.seed(0)
X = 2 * np.random.rand(100, 1)
y = 3 * X + np.random.rand(100, 1)
# Add a constant term (intercept) to the independent variable
X = sm.add_constant(X)
# Create a linear regression model
model = sm.OLS(y, X).fit()
# Calculate the skewness and kurtosis of residuals
residual_skew = skew(model.resid)
residual_kurtosis = kurtosis(model.resid)
# Display the skewness and kurtosis of residuals
print(f"Skewness of Residuals: {residual_skew:.4f}")
print(f"Kurtosis of Residuals: {residual_kurtosis:.4f}")
Skewness of Residuals: -0.1913
Kurtosis of Residuals: -1.0671
We can also obtain this information by using print(model.summary()):
print(model.summary())
OLS Regression Results
==============================================================================
Dep. Variable: y R-squared: 0.975
Model: OLS Adj. R-squared: 0.974
Method: Least Squares F-statistic: 3766.
Date: Mon, 13 Jan 2025 Prob (F-statistic): 5.22e-80
Time: 12:20:31 Log-Likelihood: -13.196
No. Observations: 100 AIC: 30.39
Df Residuals: 98 BIC: 35.60
Df Model: 1
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
const 0.5581 0.054 10.417 0.000 0.452 0.664
x1 2.9683 0.048 61.365 0.000 2.872 3.064
==============================================================================
Omnibus: 19.276 Durbin-Watson: 2.031
Prob(Omnibus): 0.000 Jarque-Bera (JB): 5.354
Skew: -0.191 Prob(JB): 0.0688
Kurtosis: 1.933 Cond. No. 3.58
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.
9.1.16.8. Condition Number (Cond)#
The condition number, often denoted as “Cond,” is a metric used to assess the multicollinearity (high correlation) among predictor variables in a regression model. It provides insight into the stability of the regression coefficients and the potential for large changes in the estimated coefficients due to small changes in the data.
How the condition number works:
Objective: The primary goal of examining the condition number is to understand whether the predictor variables in the model are highly correlated with each other. Multicollinearity can lead to unstable coefficient estimates and difficulties in interpreting the contributions of individual variables.
Calculation: The condition number is calculated based on the eigenvalues of the correlation matrix of the predictor variables. Specifically, it is the ratio of the largest eigenvalue to the smallest eigenvalue. Mathematically:
(9.34)#\[\begin{equation} \text{Condition Number (Cond)} = \sqrt{\frac{\lambda_{\text{max}}}{\lambda_{\text{min}}}} \end{equation}\]Where:
\( \lambda_{\text{max}} \) is the largest eigenvalue of the correlation matrix.
\( \lambda_{\text{min}} \) is the smallest eigenvalue of the correlation matrix.
Interpretation: The condition number provides information about the severity of multicollinearity:
A low condition number (close to 1) indicates minimal multicollinearity. The predictor variables are not strongly correlated with each other, and the model’s coefficients are stable.
A high condition number (much greater than 1) indicates strong multicollinearity. The predictor variables are highly correlated, potentially leading to instability in the coefficient estimates. A high condition number suggests that small changes in the data could result in large changes in the estimated coefficients.
Implications: High multicollinearity can make it challenging to interpret the individual contributions of predictor variables and can result in inflated standard errors, making some coefficients appear statistically insignificant when they might not be. It’s important to address or mitigate multicollinearity to improve the model’s reliability.
Example:
import numpy as np
import statsmodels.api as sm
# Generate sample data
np.random.seed(0)
X = 2 * np.random.rand(100, 1)
y = 3 * X + np.random.rand(100, 1)
# Add a constant term (intercept) to the independent variable
X = sm.add_constant(X)
# Create a linear regression model
model = sm.OLS(y, X).fit()
# Calculate the condition number of the design matrix
condition_number = np.linalg.cond(X)
# Display the condition number
print(f"Condition Number of Design Matrix: {condition_number:.4f}")
Condition Number of Design Matrix: 3.5825
We can also obtain this information by using print(model.summary()):
print(model.summary())
OLS Regression Results
==============================================================================
Dep. Variable: y R-squared: 0.975
Model: OLS Adj. R-squared: 0.974
Method: Least Squares F-statistic: 3766.
Date: Mon, 13 Jan 2025 Prob (F-statistic): 5.22e-80
Time: 12:20:31 Log-Likelihood: -13.196
No. Observations: 100 AIC: 30.39
Df Residuals: 98 BIC: 35.60
Df Model: 1
Covariance Type: nonrobust
==============================================================================
coef std err t P>|t| [0.025 0.975]
------------------------------------------------------------------------------
const 0.5581 0.054 10.417 0.000 0.452 0.664
x1 2.9683 0.048 61.365 0.000 2.872 3.064
==============================================================================
Omnibus: 19.276 Durbin-Watson: 2.031
Prob(Omnibus): 0.000 Jarque-Bera (JB): 5.354
Skew: -0.191 Prob(JB): 0.0688
Kurtosis: 1.933 Cond. No. 3.58
==============================================================================
Notes:
[1] Standard Errors assume that the covariance matrix of the errors is correctly specified.