6.2. DataFrame and Series Indices#
6.2.1. DataFrame Indices#
In Pandas, a DataFrame is a two-dimensional labeled data structure with columns that can be of different data types. Each column in a DataFrame is a Pandas Series, and the entire DataFrame has both row and column indices [Pandas Developers, 2023].
Row indices can be customized or left as default. The default row index is a sequence of integers starting from 0. However, you can set a specific column to be the index or assign custom index labels to rows.
Example:
import pandas as pd
import numpy as np
import string
# Define the number of rows
n = 10
# Generate random data with n rows and 2 columns
data = np.random.randint(0, 100, size=(n, 2))
# Generate letters from A to Z for index labels
index_labels = list(string.ascii_uppercase)[:n]
# Create a DataFrame with random data, named columns, and custom index
df = pd.DataFrame(data = data,
columns=['Col 1', 'Col 2'],
index=index_labels)
# Print the DataFrame
print("Generated DataFrame:")
display(df)
Generated DataFrame:
| Col 1 | Col 2 | |
|---|---|---|
| A | 5 | 54 |
| B | 98 | 82 |
| C | 49 | 62 |
| D | 93 | 80 |
| E | 44 | 13 |
| F | 35 | 39 |
| G | 10 | 0 |
| H | 63 | 13 |
| I | 34 | 80 |
| J | 23 | 49 |
6.2.2. Series Indices#
A Series is a one-dimensional labeled array in Pandas. Like DataFrames, Series also have indices, which provide labels for each element in the Series. The default index for a Series is similar to the row index in a DataFrame (a sequence of integers starting from 0). However, you can customize the index with labels [Pandas Developers, 2023].
Example:
import pandas as pd
import numpy as np
import string
# Define the number of rows
n = 10
# Generate random data with n rows
data = np.random.randint(0, 100, size=n)
# Generate letters from A to Z for index labels
index_labels = list(string.ascii_uppercase)[:n]
# Create a Pandas Series with random data and custom index
series = pd.Series(data, index=index_labels)
# Print the Series
display(series)
A 32
B 94
C 77
D 66
E 30
F 12
G 82
H 13
I 98
J 98
dtype: int32
Indices are crucial in Pandas as they enable powerful data alignment during operations. When performing operations on DataFrames or Series, Pandas uses the indices to match elements correctly, even if the data is not in the same order.
Indices can be used for selection, alignment, merging, and other operations, making data manipulation more intuitive and accurate in Pandas.
6.2.3. Index Alignment in Pandas#
Index alignment is a powerful feature in Pandas that facilitates seamless and efficient data manipulation and computation across Series and DataFrames. When performing operations involving multiple data structures, Pandas aligns the data based on their indices, ensuring that calculations occur between corresponding elements.
This alignment is crucial for accurately combining, comparing, and performing arithmetic operations on data with different structures but related indices.
Example - Series Alignment:
import pandas as pd
# Create two Pandas Series
data1 = pd.Series([10, 20, 30], index=['A', 'B', 'C'])
data2 = pd.Series([5, 15, 25], index=['B', 'C', 'D'])
# Perform element-wise addition on the Series
result = data1 + data2
# Display the result using the appropriate function for a Series
print(result)
A NaN
B 25.0
C 45.0
D NaN
dtype: float64
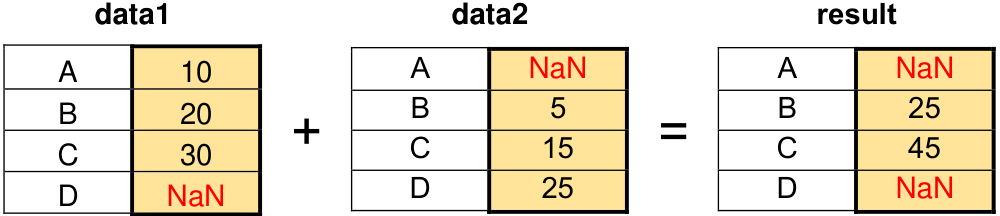
Fig. 6.1 Index Alignment Example.#
In this example, the Series data1 and data2 have different indices. However, when the addition operation is performed, Pandas aligns the data based on their indices. As a result, calculations are only performed where indices match, and NaN (Not a Number) values are introduced for indices that do not match.
In data analysis, “NaN” stands for “Not a Number.” It is a special value used to represent missing or undefined data in numerical or floating-point data types.
6.2.4. Create new columns#
You can assign new values to rows and columns even if they don’t exist in the DataFrame.
# Setting new values, creating rows if needed
df.loc[new_row_label] = new_data
df['new_column'] = new_data
Advantages:
Convenient for adding new rows or columns without explicitly modifying the DataFrame shape.
Enables quick DataFrame expansion without explicit resizing.
Disadvantages:
Can lead to the unintentional creation of new rows or columns if not used carefully.
Might not be suitable for cases where strict control over data insertion is required.
Example:
import pandas as pd
# This example is from
# https://pandas.pydata.org/docs/getting_started/intro_tutorials/05_add_columns.html
# The Air Quality NO2 dataset if from
# http://dhhagan.github.io/py-openaq/index.html
df = pd.read_csv('https://raw.githubusercontent.com/pandas-dev/pandas/main/doc/data/air_quality_no2.csv')
print(r'Air Quality NO2:')
df.head(8)
Air Quality NO2:
| datetime | station_antwerp | station_paris | station_london | |
|---|---|---|---|---|
| 0 | 2019-05-07 02:00:00 | NaN | NaN | 23.0 |
| 1 | 2019-05-07 03:00:00 | 50.5 | 25.0 | 19.0 |
| 2 | 2019-05-07 04:00:00 | 45.0 | 27.7 | 19.0 |
| 3 | 2019-05-07 05:00:00 | NaN | 50.4 | 16.0 |
| 4 | 2019-05-07 06:00:00 | NaN | 61.9 | NaN |
| 5 | 2019-05-07 07:00:00 | NaN | 72.4 | 26.0 |
| 6 | 2019-05-07 08:00:00 | NaN | 77.7 | 32.0 |
| 7 | 2019-05-07 09:00:00 | NaN | 67.9 | 32.0 |
The goal is to express the \(NO_2\) concentration at the London station in milligrams per cubic meter (mg/m³). This conversion is achieved under the conditions of 25 degrees Celsius and 1013 hPa pressure, using the specific conversion factor of 1.882 (Further information can be found here).
df["london_mg_per_cubic"] = df["station_london"] * 1.882
df.head(8)
| datetime | station_antwerp | station_paris | station_london | london_mg_per_cubic | |
|---|---|---|---|---|---|
| 0 | 2019-05-07 02:00:00 | NaN | NaN | 23.0 | 43.286 |
| 1 | 2019-05-07 03:00:00 | 50.5 | 25.0 | 19.0 | 35.758 |
| 2 | 2019-05-07 04:00:00 | 45.0 | 27.7 | 19.0 | 35.758 |
| 3 | 2019-05-07 05:00:00 | NaN | 50.4 | 16.0 | 30.112 |
| 4 | 2019-05-07 06:00:00 | NaN | 61.9 | NaN | NaN |
| 5 | 2019-05-07 07:00:00 | NaN | 72.4 | 26.0 | 48.932 |
| 6 | 2019-05-07 08:00:00 | NaN | 77.7 | 32.0 | 60.224 |
| 7 | 2019-05-07 09:00:00 | NaN | 67.9 | 32.0 | 60.224 |